Iris.ai has recently partnered with Materiom to help building the world’s largest database and research community of material science knowledge to aid the transition away from petrochemicals. With the automated extraction and systematizing of the content, recipes and ensuing properties of materials from more than 50,000 articles, Materiom will have laid a solid foundation for their groundbreaking community of researchers. This database will then be published on Materiom’s platform to speed up R&D processes and market entry of regenerative materials. This will ultimately lead to reduced plastics pollution, and the creation of a materials economy that benefits ecological regeneration.
“We are excited to collaborate with such a great team of enthusiastic professionals and scientists like Materiom. Seeing how our Extract tool can extract such a big number as 50k documents and extract data from a wide range of renewable materials is thrilling. Even more, as we are contributing in that way to a more sustainable world.” – says Kimberly Holtz, Key Account Manager at Iris.ai.
“Iris.ai is helping us get to scale with our open database, a resource that will accelerate regenerative materials R&D” – Alysia Garmulewicz, Founder and Co-CEO of Materiom, states.
Keep an eye on our blog for project updates and information when the database is available this year. If you think that we can help with your problem, contact us!
About Materiom
Materiom is an open access platform for creating sustainably-sourced biomaterials, made from locally-abundant natural ingredients. The Materiom community includes material scientists, designers, engineers, data scientists, and sustainability experts. The project supports companies, cities, and communities in creating and selecting materials sourced from locally abundant biomass that are part of a regenerative circular economy.
In the last blog post we introduced our new shiny tool – the Researcher Workspace. A place where you decide how to do your research process and apply the AI-based tools you need. In this post we want to introduce you to some concrete client use cases and explain how we set up their workspace for their unique process to address their needs.
Food safety reviews
We are working with a niche review team that needed to perform a wide range of food safety related searches to keep the population safe. The team needed a better way to do full interdisciplinary literature searches on a broad variety of topics, expanding beyond their individual areas of expertise. They have a simple Workspace with an Explore tool, where the reviewer can input a human language description of the research, without the need for comprehensive vocabulary understanding. Iris.ai uses contextual key terms, synonyms and hypernyms to build a ‘fingerprint’ it can match to other papers and presents a visual map with overview over topics and relevant research papers.
Exploratory R&D for a biotech Company
This collaboration is with a biotech company that has extensive R&D efforts in mapping out a knowledge graph of real world data (e.g any microorganism they locate in their field or lab work) that will lead to new insights for their product development. Their starting point is an entity (e.g bacteria, parasite) in a given context – and then search for all relevant knowledge, analyze all articles found, extract the key data points and summarize the findings, with the goal of connecting information in a database.
Pharmacovigilance for a Contract Research Organization
This CRO performs regular contract work where they do limited, specific and rapid literature searches for their clients across a variety of medical devices and drugs.
They are regularly undertaking post market surveillance and pharmacovigilance studies. Usually each project is about 80 hours. In order to reduce the time the team spends on the manual work, the CRO has an Iris.ai Researcher Workspace setup where they upload their search results (≈500 articles), apply a range of smart filters (entities, data points and context descriptions) to instantly filter down the list to the ≈30 articles of interest. Then the tool automatically extracts all clinical data points of relevance into a database – both to a short collection of summarizing data points and to a comprehensive 500-point collection. All actions are recorded and a final report draft is automatically generated.
Drug repurposing for an interdisciplinary research group
A Californian research group, funded by the Canadian government, is searching broadly for new drug candidates from western, Chinese and herbal medicine for a specific medical situation. Each researcher starts from an idea, doing a PICO style natural language text search and filters, across a variety of western and alternative research articles. Once an interesting approach is found, the articles are collected and all relevant clinical data is extracted and used to populate a database, made openly accessible to researchers across the world.
IP analysis for a steel conglomerate
This world-leading steel manufacturer strategically monitors filed IP to spot new market opportunities, but extracting detailed experiment data from patents is incredibly time consuming. Their Workspace allows researchers to provide the system with one or several patents, using that input to identify a range of other patents based on the content. The identified patents can then with one click be sent for extraction, where thousands of data points in text and tables are extracted, linked and mapped to their desired format.
Academic reviews
Librarians are always searching for better ways to help their students and researchers find the right literature. An academic-oriented Researcher Workspace is connected to all relevant literature sources and allows exploratory searches based on problem descriptions. The tool, with its visual search interface, is especially loved by Master and PhD candidates early in their research careers, with still-unknown topics to explore broadly.
Key takeaways
Each presented use case is distinct, but in every instance we found a suitable process to help companies, research institutes and universities with their scientific knowledge processing needs. Our tools are customized and trained on each client’s domain to optimize results. If you think that we can help you out, contact us!
CORE and Iris.ai are extremely pleased to announce the initiation of a new research collaboration funded by the Norwegian Research Council.
Discovering scientific insights about a specific topic is challenging, particularly in an area like chemistry which is one of the top-five most published fields with over 11 million publications and 307,000 patents. The team at Iris.ai have spent the last 5 years building an award-winning AI engine for scientific text understanding. Their patented algorithms for identifying text similarity, extracting tabular data and creating domain-specific entity representations mean they are world leaders in this domain.
The AI Chemist project is a collaboration between Iris.ai and The Open University, Oxford University, Trinity College, Dublin and University College, London. CORE is a not-for-profit platform delivered by The Open University in cooperation with Jisc that hosts the world’s largest collection of open access scientific articles. As of February 2022, the CORE dataset provides metadata information (title, author, abstract, publishing year, etc.) for approximately 210 million articles, and the full text for 29.5 million articles.
Working in partnership with CORE developers and researchers, Iris.ai will now leverage the vast quantities of research papers available in the CORE dataset. This dataset will be employed in improving the quality of text extraction from scientific literature from Chemistry focused domains. The output of this phase will support Iris.ai and The AI Chemist in understanding reasoning and inference across research papers.
Currently, the state of the art in the chemical domain is a combination of direct manual evaluation of text documents, social networks and curated, but incomplete databases. The manual nature of these approaches makes discovery of novel application areas immensely time consuming. The goal is to develop a set of algorithms that can machine read vast amounts of scientific literature and data, discover and detect mentions of entities of interest and their relations (such as chemical products, compounds, properties, processes, applications, etc.) and connect these pieces of information to build an increasingly complex knowledge graph.
Dr Ronin Wu, Research Lead and Head of Research Collaboration at Iris.ai, said: “Iris.ai are extremely pleased to be partnering with CORE on the AI Chemist project and we’re looking forward to seeing some exciting new developments with our AI models”.
Dr. Petr Knoth, Head of CORE and Senior Research Fellow in Text and Data Mining, said: “This cooperative research project will put CORE at the forefront of the global effort to create open scholarly knowledge graphs. As part of this project we will use state-of-the-art machine learning approaches to address problems including topic / themes extraction, affiliation extraction, deduplication and citation function detection. With the demise of Microsoft Academic Graph at the end of 2021, we see on a daily basis how much this is in demand among CORE users. ”
We at Iris.ai are on the edge of our seats with excitement with the upcoming launch of the Researcher Workspace! Why, you ask? The new tool suite is content focused, and allows you to follow your own workflow and processes. It can easily be adapted to your organization’s needs. The Researcher Workspace includes the modules: Search, Filter, Analyze, Extract, Summarize, Automate, Report. In this blog post we want to give you an overview of the new tool.
What differentiates the Researcher Workspace from our current tools is that there is no structured process that you must follow. You can upload your data from any source to your dashboard and decide what you want to do with it. Some of the ways you’ll be able to input information will range from using external URLs, cloud drives, open-source repositories to using files on your own device.
Once you have added documents that you want to investigate further, your main point of interaction with the data will be the dataset preview. It will allow for document preview so you know what you are playing with and the outputs from the other tools will be accessible in this one unifying place.
Search
Upon selecting at least one dataset, you will be able to search for literature by giving the system a self-written text or a link to a research paper – much like our existing Explore tool. As a result, you will get a list/map of relevant papers including their relevance scores. The results will automatically create a new dataset with an automatic context filter related to the input. This tool is great when you don’t really know what you are looking for, allowing you to do a broad search on a topic.
Analyze
After your dataset is created, you can use our word and topic analysis tool to filter through your results – similarly to our existing Focus tool, but more flexible. You can use generated words and topics as inclusion/exclusion criteria on your dataset so you can filter through it.
Filter
You can also filter your data using metadata filters for (1) publication dates and (2) add/remove repositories or (3) create filters using context descriptions based on your free-text. The context filter is saved automatically, so you can use it later on a different dataset. Context filters are especially useful when you are trying to filter something that cannot be described with one word but rather by using one or multiple descriptions.
Extract
You can as well automatically extract the data from selected documents into a tabular format, which has been pre-approved and made available by Iris. This feature allows the extraction of different types of data possibly corresponding to the different type of document selected for the extraction.
Summarize
The Iris.ai Workspace comes with a configurable summarization engine. You can quickly get summaries of the articles and check if there are any novel and relevant findings in them. So you can skim a lot of content faster. The engine can rapidly produce summaries of one or multiple abstracts or of one or multiple full text documents. The summarization that Iris.ai uses is abstractive which captures the context of summarized text. The generated summary contains new phrases and sentences that may not appear in the source text.
Report
If you want to document your search, we can prepare customized automatic report generation for you. The report can contain the number of searches, most used filters and more.
Every research process is a little different, and your Research Workspace will enable any workflow. In the future blog posts we will share with you more details, so stay tuned!
We are excited to announce that a new version of our tools – Iris.ai 7.3 is available now! As always we’ve improved current features, fixed bugs and added some brand new shiny features ✨
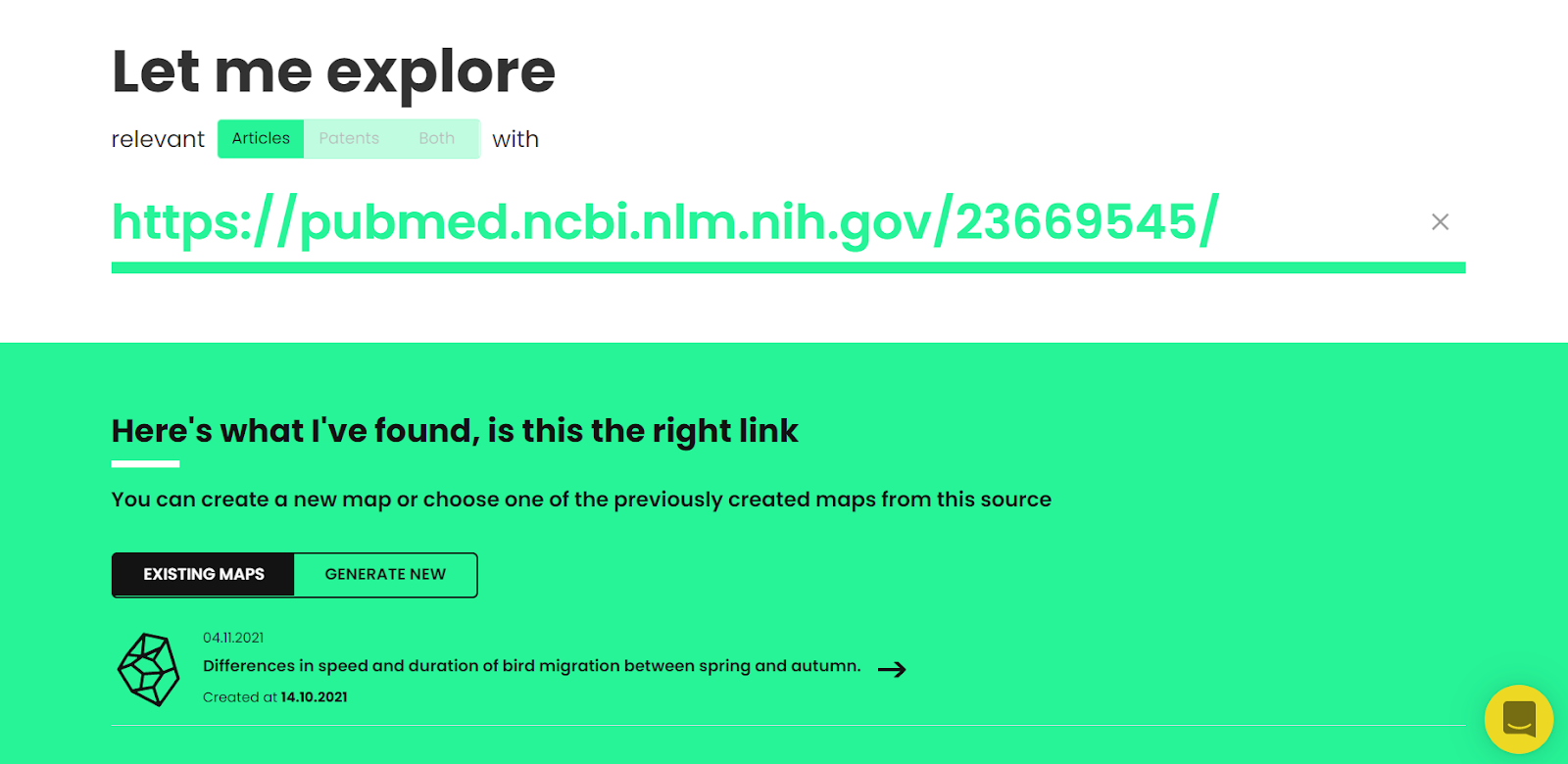
When you are using the Explore tool to generate a map (using URL or problem statement) now our engine will recommend to you all the maps that have already been generated with this same title or using the same link. There you are able to choose whether you’d like to view an already existing map or to generate a new map.
Export your results in EndNote
Now in both Explore and Focus tool you can export your results in EndNote format.
Other improvements
We always work hard on improving our tools but it’s not always visible from the user perspective. We have fixed bugs with pop ups, improved the dark mode, updated Django and Python and many many more!
If you have any features on your wish list that haven’t been created yet, let us know at support@iris.ai ✌️
Anita Schjøll Brede, Co-Founder and CEO at Iris.ai
We will not back down, but keep being adamant supporters of Open Access until all of the world’s scientific knowledge, especially the tax-funded kind, is free and openly available to everyone.
Five years ago, we set out to change the world through science. People told us we were bold and a bit insane; we were up against a daunting technical challenge – scientific text understanding – and a powerful publishing industry that does not welcome newcomers. Critics claimed that the world of Open Access was not powerful enough for literature reviews, and that it would never change. From the impact factor to the citation system and the urgent need to ‘publish or perish’, the challenges of the research world were vast. Where would we even start?
Open Access movement
We kept it simple. We started with our favourite people, the academic researchers, and one of their most general frustrations: the literature reviews. In beginning, we connected to the Directory of Open Access Journals, which had about 2 million Open Access (OA) articles. It wasn’t much, but it was something.
As our products matured and improved, and the company and number of users grew, more and more Open Access articles were published. Today we connect with our friends at Core.ac.uk for access to 200 million metadata entries of OA articles. We connect to PubMed for 27 million articles, both open access and paywalled. We connect to the entire US Patents Office, the CORDIS database of funded research progress, and to the paywalled content of our clients, of course.
One blocker remains: the major publishers who won’t allow us to machine-read their publicly available titles and abstracts. (For now, we’re working our way around it with paying clients.) We will not back down, but keep being adamant supporters of Open Access until all of the world’s scientific knowledge, especially the tax-funded kind, is free and openly available to everyone.
Relentless focus
Access to scientific content aside, what we have managed to achieve in the last five years is exciting! We’ve implemented and are developing world-leading solutions on document similarity and word embeddings. Our core engine is among the world’s most sophisticated when it comes to scientific text understanding. And, what I am perhaps more proud of than anything; we’ve remained focused. Countless times have others asked for tools for other kinds of material – from legal texts to Twitter messages. We have repeatedly stood our ground, rejected what could have been financially rewarding opportunities, and kept working on what matters to us – and, we believe, to the world.
And, most importantly, we have built a suite of tools that are helping thousands of students and researchers across the world – entirely bypassing the biased citation system – to do the most boring part of their job way more efficiently. My favorite moments five years on are when people tell me we totally saved their thesis work, or their project, or their research grant application.
The road ahead
There are still challenges remaining. There are technical hurdles as we work with domain aware embeddings. We continue to fight for access to paywalled content and the ability to machine-read their abstracts. And we face a range of problems in the world of making scientific research more accessible, navigable, and understandable.
— Export your bookmarks, bulk actions, repository overview and more…
We’re very excited to say we launched the latest version of our academic tools this week, version 6.1! As always, we’ve improved the backend and done some bug fixes to ensure you have a smooth experience using Iris.ai — but we have of course some juicy features for you as well.
I’ve listed the new features below. Do you want to try them out? Register and sign in to get started with a free account. We hope you enjoy the new update! ????
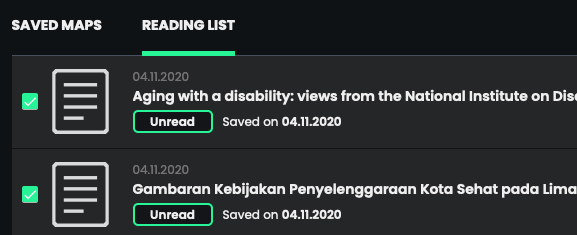
Now you can finally export all the papers you have bookmarked. Simply, click the brain icon in the top right corner, go to your reading list and select the papers you’d like to export. You can choose between CSV and BIBTEX.
Bulk actions
We’ve added checkboxes in front of every entry, allowing you to bulk actions. For example, exporting multiple papers.
Free or premium?
If you were ever in doubt, now you can see whether you’re subscribing to a premium or free version of Iris.ai — whether you’re an individual subscriber or a university member.
“But where are all these papers coming from?”
One question our users often ask us is, “but where are all these papers coming from?” Now we’ve given you a neat way to quickly check the repositories in which the papers were found. (Also, hot tip: if you find repositories in your list that you don’t want to see papers from, use the repository filter to exclude them!)
Undo/redo actions in a session
When you’re editing your map in hierarchy, you’re now able to undo and redo all the actions you’ve done in that session.
Hierarchy Editor: Duplication of concepts
Using the hierarchy editor, there are sometimes subconcepts that are highly relevant under multiple top concepts. Now we’ve given you the ability to duplicate the concepts so you can place them in several parts of the fingerprint — more customization and control over the fingerprinting process.
If you have any features on your wish list that haven’t been created yet, let us know at support@iris.ai!
We are a company that do our best to put impact first. Over the last few weeks we have found ourselves initially stunned and perplex, and eventually a tad bit overwhelmed, by the COVID-19 pandemic and the SARS-CoV-2 virus causing it. What can a small startup team do, beyond sharing our advice on remote work (we’ve been remote since the start of the company), do our best to keep our employees safe and sane and stay hopeful that our revenues will not decline entirely to zero?
We can’t do much. But if you are a researcher, medical professional or problem solver, you can. And we can help.
For anyone working on any aspect of research around COVID-19, whether on the epidemiology, virology, biology, psychology or anything else – and whether you are an academic or a concerned citizen – we hereby invite you to join Iris.ai, and your account will then be added to the premium access COVID-19 research group. Our only requirements are that your work is on the current pandemic, and that you allow your findings through Iris.ai to be shared publicly.
Iris.ai puts her engine to the task of COVID-19
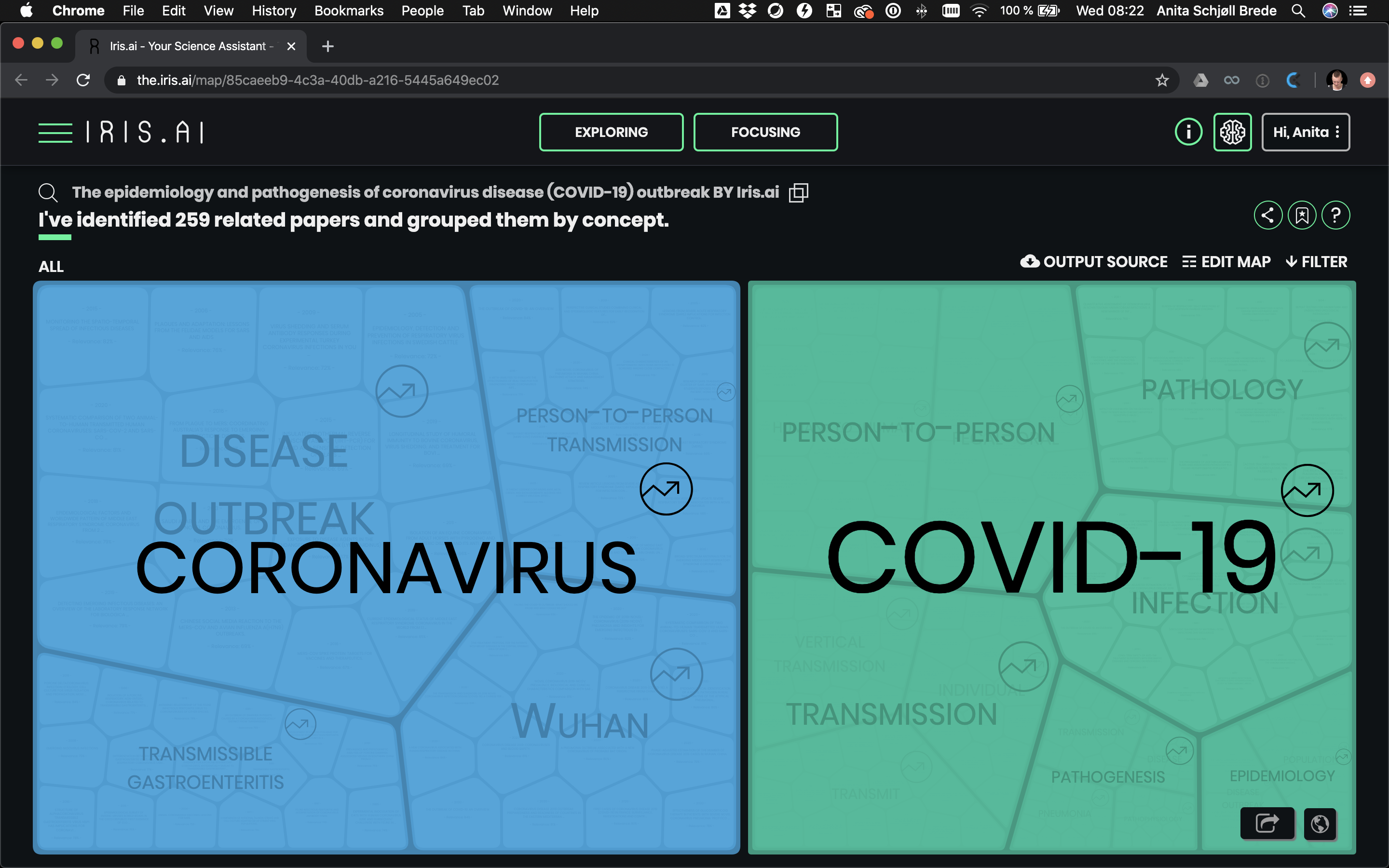
Our tools can help you find the right research for the problem you face. Here, for example, is an interesting map on “The epidemiology and pathogenesis of coronavirus disease (COVID-19) outbreak”.
The amazing humans at the Allen Institute / Semantic Scholar have worked on an open dataset of almost 30,000 articles related to COVID-19. This, plus about 120 million other research papers (Open Access), are all connected to the Iris.ai tools.
On April 7th, at 8am CET and 5pm CET we will host free webinars for everyone joining the premium COVID-19 research group (register here), to help you get started, answer all your questions, and do anything we can to help your research process run smoothly. Please sign up to get the details.
Everyone is of course also welcome to join our monthly online workshops that walk you through the premium tools, whether or not you’re a COVID-19 researcher. Have a look at our Facebook events for upcoming dates.
In order to get set up with free access to the COVID-19 Iris.ai premium organization, here is what needs to happen: 1. You sign up for an account on https://the.iris.ai/auth/registration 2. Then send an email to order@iris.ai from the same email account and mention COVID-19 in the subject. 3. We will then add you to the premium group, and notify you when it’s done so you can log in, accept the terms and get working.
We will keep this premium access open to you for a minimum of three months – until end of June 2020 – and it will be extended unless the pandemic is over.
We don’t know what each one of us can do on our own, but we know how much power there is in a world coming together against a common enemy. We hope our tools might help you in the process. Let’s see if we can save some lives.
If you are not a researcher, but want to help, you can do so by sharing this announcement with the people in your network who might have a use for it.
The past and the future of chemistry as we know it.
In 1776, chemist and mechanical engineer James Watt invented the Watt steam engine, which was fundamental to the changes brought by the Industrial Revolution. Ever since – and potentially even before – an understanding of chemistry has been the foundation for our technological development, and there is no reason to believe that this holds any less true for the future. Whether we need more sustainable materials or biodegradable fuel to reduce our carbon emissions, new materials allowing us to travel to space or terraform Mars, novel ways of ensuring that every person on this planet is properly fed or understanding how we can handle an ocean filled with plastic particles, chemistry is going to be absolutely foundational.
What has enabled such a thorough understanding of chemistry pertains to the field’s formalism – the same as for maths and physics. This means structured approaches to unifying language so that any chemist anywhere can talk about anything from the basic elements, via molecular formulas to complex synthesis procedures in the same way. This structured way of communicating with each other has allowed rapid progress in this scientific field.
However, formalism has its downsides: when you simplify a process or a thought process into a unified language, inevitably there will be a loss of information on the way. Much like a compressed image is easier to share and still shows the same motive, but is pixelated, so can formalist research results be easier to convey, transmitting a general idea of the approach, whilst missing the finer details. Ideas are compressed to formulas, long research papers compressed to abstracts, novel ideas compressed to a 140 character tweet, detailed lab notes compressed to summaries.
In chemical research, this ‘compression’ has been required because of human limitation – but today, it isn’t required anymore. Computers have already allowed a much broader and larger volume of shared knowledge – which in itself makes absolute formalism tricky. And thanks to advances in AI, we are rapidly approaching a new frontier for research.
With new AI advances, machines can help researchers find what other researchers have done, ‘translate’ it into that researchers’ current context, and get a much higher clarity on how and why the solutions or conclusions were reached – without the information loss built into the current process. The machine will have all the necessary information–as there is no information loss–to communicate or ‘translate’ the exact relevant pieces between the researchers. This will truly be a new paradigm of chemical research (and beyond).
The chemical industry is trying to solve a 21st-century problem with a 20th-century approach
The state of scientific knowledge today is as if we had millions of cities (knowledge nodes) but only small footpaths through the woods to connect them – and no reliable map. However, with recent advances in AI technology, we are now able to build some serious digital highways, connecting all these ideas and people.
Discovering scientific insights about a specific topic is challenging, particularly considering that chemistry is one of the top-five most published fields with over 11 million publications and 307,000 patents. Moreover, the pace at which worldwide scientific knowledge expands is staggering. In 2016 alone, almost 2.2 million scientific articles were published and this output is doubling every nine years. In the process of trying to navigate, extract information from, and understand all this material, simplifications are being made and too much information is lost or missed. This is hampering global progress, and frustrating both the individual researchers trying to wrangle all this information and their R&D managers responsible for the department delivering quality commercially feasible results.
We have reached a point where a researcher will know that the answer they are looking for is likely to be ‘out there somewhere’, but there is no way for them to find it. The reasons for this include:
a) there is not one table in one location where all the information one might need is stored;
b) researchers are no longer able to adhere strictly to the previously helpful formalist rules as interdisciplinarity and creativity is (or should be) the new norm;
c) no-one documents and disseminates information in the exact same way; and, at the end of the day,
d) there is simply too much knowledge for a human researcher to assimilate.
This causes major challenges in finding the right knowledge, whether the answer is a quick and simple one (“what other applications are there for my compound?”) or way more complex (“if we extract the knowledge from these three papers, these ten patents, and this product sheet… doesn’t that mean we have an entirely novel compound?”).
Chemical companies need to:
a) find ways to utilise their core competencies and existing knowledge to generate new revenue,
b) reduce the risk of lab experiments failing by having as much upfront information as possible, and
c) make their R&D process as cost-efficient as possible without compromising quality.
The best way to go about the first two challenges is leveraging existing scientific literature, but unfortunately, that is not possible today while at the same time achieving the latter.
Chemical companies’ R&D departments today are absolutely vital to the companies’ survival and ongoing success, but they are at the same time seen as a non-revenue generating “burden”: Necessary, but expensive. Very expensive.
Chemical companies’ R&D departments today are absolutely vital to the companies’ survival and ongoing success, but they are at the same time seen as a non-revenue generating “burden”: Necessary, but expensive. Very expensive. R&D managers are under pressure to deliver more results, faster, but because of the overwhelming amount of information, it is becoming increasingly difficult. At the same time, their most valuable R&D assets are their research staff, to whom searching through thousands of documents to try to find answers is just an annoying and tedious burden, far removed from the real fun work that happens in the lab. And the less the researcher reads in advance, the higher the chances are their lab experiments may fail, wasting their time and the company’s valuable budget.
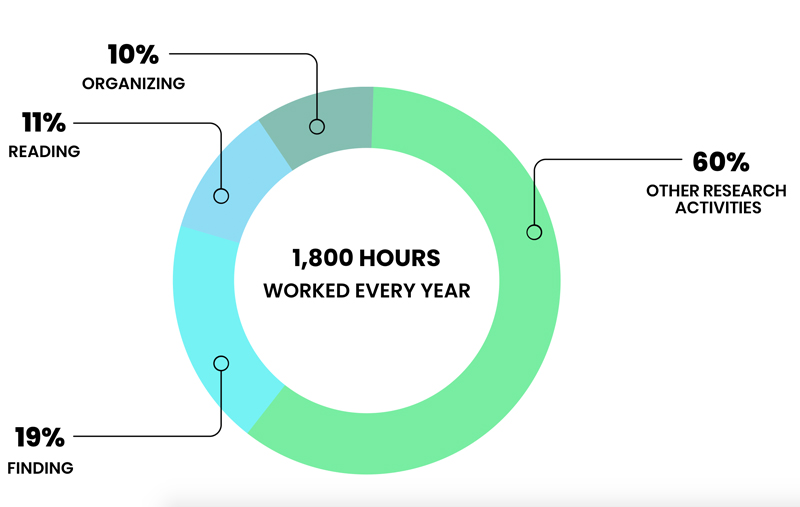
Out of an average of 1,800 hours worked every year, studies show that about 40% of a chemistry R&D researcher’s time is currently spent between finding (19%), reading (11%) and organizing (10%) existing literature. This represents a massive inefficiency.
To remain competitive and grow their market share, chemical companies need to constantly ask themselves the questions listed below, and efficiently find their answers from existing literature (something not fully possible today, based on the current state of affairs, including the productized available technology):
What are new uses for an existing compound?
How can we change the properties of an existing material?
What other synthesis pathways will improve our existing manufacturing process?
What compounds with specific properties can be used as substitutes in an existing application area?
What new chemical substances can we create by combining known compounds, and thus a new market?
Of all of the above questions, what approaches are more sustainable, as we are under continued pressure to reduce our environmental footprint?
The only way for industrial chemists to potentially find answers is relying on limiting keyword-based search engines, summarized findings that ‘everyone’ has access to and following key researchers on social media channels to see what they are up to. After that, no matter how the papers are found, they still need to manually screen and review existing chemical literature one paper at a time. But as we have shown above, this is a very challenging task with very slim chances of finding what is needed. And even if they should be diligent and have a large enough team to be able to stay on top of existing literature – they can not also have time to crunch the findings, test the knowledge, validate the hypotheses in the lab and then publish the results as well. This means that, based on the current state of existing knowledge management solutions, there is very little time for actual innovation. Chemists then have no other alternative, but to rely on their own experience, limited knowledge, rules of thumb, outdated tools and the occasional dumb luck. Moreover, ‘blind’ trial and error leads to repeatable, mundane and time-consuming tasks, ending in unpredictable results – until hopefully a solution is found, although with low confidence it was the best solution or a good use of time.
Innovate or die must be adopted as the key mantra by the chemical sector if those companies want to remain competitive.
The chemical industry is today trying to solve a 21st Century problem (increased speed-to-market, lower product margins and cut-throat global competition amidst an overload of information) with a 20th-century approach (slow, outmoded and error-prone guesswork).
Chemical companies are coming under increased pressure to get smarter in the current wave of digitization, amidst new technological challenges, shrinking product life cycles and the rush to commoditize products. They simply need to increase the pace of innovation.
Innovate or die must be adopted as the key mantra by the chemical sector if those companies want to remain competitive. This involves embracing innovative ways to research and develop new commercial products.
The world needs science. Complex challenges ranging from climate change to preventive medicine require us to put our best minds together to solve them. And we do live in a world where more scientific knowledge is available to us than ever before — but the irony is that our politicians doubt its legitimacy, our researchers are pressed for time and resources do not have capacity to communicate across even the closest alleyways of a university, publishing houses generate profit by keeping vital results hidden behind heavy walls, and go after those who breach them with deadly force. In addition, the big software players are opaque and seemingly impossible to hold accountable for their data, their algorithms and the implications of these. In spite of Tim Berners-Lee creating the internet to share scientific knowledge, it seems we have only come marginally further today than we had back then.
Two years ago at Iris.ai we sat out on quite the ambitious journey: to build what we call an “AI Scientist”, a system that can augment our human intelligence by connecting the dots of all of the world’s research. The months since have been filled with hard work, progress, setbacks, a lot of rejections — but also so much love, support, understanding and encouragement from our wonderful community.
In these two years we’ve built a system that reduces a human’s time to map out existing scientific knowledge with up to 90% , while increasing serendipity and interdisciplinary discovery. This is the first important step towards what we call the Knowledge Validation Engine, a core feature of the AI Scientist. We have a dedicated team that has built this, we have a number of budding university collaborations and we have a group of lovely investors who believe in us and we’ve published several open access research papers. Most important, this past year we’ve seen an amazing community of AI trainers grow up around us — more than 8,000 individuals who volunteer their time to help Iris.ai learn. We’ve seen a desire to be part of our journey, a wish to help us achieve our mission, a community coming together to tell us that what we do is important. We have done our best to honor their help, but we have not done enough.
Transparency, openness and fighting bias have been our core values from day one, but we find ourselves not living up to our own standards. We find ourselves torn between servicing big corporate clients and satisfying a European venture capital community single-mindedly focused on revenue (with some very honest impact focused exceptions) on one hand — while also trying to bring what we build out to as many people as possible.
For us to truly make impact in the world, it is not enough to build some great tools, we need to disrupt and uproot an entire industry. We can not do that on our own — it’s a grassroots challenge. We need your help.
Scientific knowledge is arguably the ultimate decentralized application. It is not controlled by a central agent, is individual node-independent, is exposed to public scrutiny and constant challenge and is preciously valuable for a large and fast growing cohort of current and future users.
The technology development of this decade is thrilling, and today we are taking advantage of a new opportunity. Utilizing the decentralized nature of the blockchain, we have decided to give power to our community by tokenizing our functionalities— allowing anyone who contributes to the tool to generate tokens by doing so — tokens they can later use directly to access our core services.
An AI Trainer who annotates research papers, a coder who commits to our increasingly open source code, a user who reports a bug or a researcher who uses the Iris.ai Knowledge Validation Engine to publish their research Open Access — they will all be rewarded with tokens for contributing. The tokens can be used to access any of the Iris.ai tools. All token holders will have a voice, have transparent insight into our core technology and will be asked to hold us accountable to openness and de-biasing our algorithms and data. And as both corporates purchase access to the Iris.ai tools and the the algorithms of Iris.ai improve over time, the value of the tokens held by our community will increase.
We’re excited, thrilled and a little scared — as per usual, we’re traversing unchartered territory. And we can not do this alone. Please join us in making science transparent, open and accessible.
Our white paper with the details will be made available early 2018. Until then we would love your ideas, thoughts and feedback — on tokens@iris.ai or our Telegram channel.


")

")


x")