Here’s a breakdown of how R&D teams analyze and extract information from competitors’ patents, a critical process when deciding what chemicals to develop and for which applications.
Many R&D teams struggle under the heavy weight of patents they must analyze to stay competitive. To make matters more complicated, competitors often obscure new chemical compounds in patents. For example, if you need to identify all possible derivatives of a main chemical compound that your competitor has tested, the information might not be presented clearly in their patents.
We’ve seen patents where hydrogen has been annotated as ‘hydrogen’, the letter ‘H’ and as a chemical image of the atom, all in different rows and columns of a table. In other words, it’s hard for people and machines to quickly figure out the eventual form of those derivatives.
Albeit a critical task to identify market opportunities and innovate faster, manually analyzing patents is extremely laborious and time-consuming.
Read competitors’ patents faster to innovate faster
Needless to say, it’s crucial to have a thorough understanding of current and future trends in today’s competitive market. By staying up to date on your competitors’ latest developments, you’re in a position to better understand your products’ advantages and disadvantages, and where you can add value to your offerings. Moreover, designing a winning product development strategy demands a thorough understanding of both market needs as well as current offerings.
Using artificial intelligence can reduce months of manual work to minutes — and the process is pretty straight forward. Depending on the type of patents, the machine can extract up to 60 patents in 2 minutes with 90% accuracy. This enables patent analysts to spend their time analyzing the chemical compounds and make patent decisions.
How to extract information from competitors’ patents
Automating the analysis of competitors’ patents follows four steps.
1. Input: competitors’ patents
First, you upload all the patents you’d like to extract information from to the machine, similar to how you would upload documents to any software.
2. Automation: Iris.ai machine working procedure
When the patents are uploaded, our engine detects and identifies all tables and chemical compounds which have open bonds to be replaced by various substituents. The machine then picks substituents from different rows and columns, and replaces them in the correct place in the main chemical compound. The result is newly formed chemical derivatives in different formats e.g. SMILE strings, images, etc.
3. Output: all implicit derivative compounds from explicit tables
Finally, when the machine has generated all possible derivatives, it creates a table which contains information about which table they are taken from, their SMILE strings as well as their chemical structure images.
Key takeaways
To stay competitive, R&D teams sift through hundreds of patents to identify market opportunities. Developments in artificial intelligence enable them to automate the most manual tasks, to identify and extract chemical compounds in patents, freeing up time which they can spend analyzing the market and making patent decisions.
Artificial intelligence is rapidly changing the way we work in various companies and industries around the world, including the chemical industry. Organizations are adopting these technologies to accelerate processes and reduce costs, as well as saving employees from tedious, mundane tasks.
Accenture suggests that there are three ways of applying artificial intelligence in research across industries:
Reinventing the process to manage process change, rethinking standardized processes as continuously adaptive, and using AI across multiple processes.
Rethinking human-machine collaboration; how companies can have an AI-enabled culture to reskill employees to work in alliance with machines.
Utilizing data, making use of AI and data to solve previously unsolved problems and reveal hidden patterns.
In this article, we will explain how chemical researchers are applying artificial intelligence.
How chemical researchers are applying AI
There are three categories of chemical research that are affected by AI. The first category is molecule prediction — draw on known properties to predict new behavior. The second category is synthesis models, which predict how to create certain molecules in fewer steps and more reliable processes. The third is handling prior knowledge to make sense of what we already know —starting with data mining to find the right information.
1. Case studies on molecule predictions
The pharmaceutical industry is one of the front runners in AI. In February 2020 the model in “A Deep Learning Approach to Antibiotic Discovery” was created, a model that translates molecules into vectors. It starts with every atom being represented with a vector of simple properties. This is used to create a fingerprint of the molecule’s structure, which helps the neural network to learn.
The model was trained on tests with E.coli to see what molecular structures actually were antibiotic. Then it was applied to the Broad Institute’s drug repurposing hub – an open-access library of more than 6000 molecules with known biological activity. As a result, they discovered a compound called Halicin with impressive antibiotic activity, despite having a chemical structure unlike conventional antibiotics.
Following this success, the team applied their AI technique to a database known as ZINC15 — 107 million molecules were manually selected for screening. Based on the deep learning tool’s predictions, 23 compounds were chosen for further investigation. Two of these compounds showed promise against a range of drug-resistant E. coli.
In march 2020 Münster University published A Structure-Based Platform for Predicting Chemical Reactivity. The new tool is based on the assumption that reactivity can be directly derived from a molecule’s structure. It uses an input based on multiple fingerprint features as an overall molecular representation. Organic compounds can be represented as graphs on which simple structural (yes/no) queries can be carried out. Fingerprints are numeric sequences based on a combination of multiple queries. They were developed to search for structural similarities and proved well suited for use in computational models. For the most accurate presentation of the molecular structure of each compound, a large number of different fingerprints are used.
2. Finding the best synthesis method: expert system vs. machine learning
In 2018, The Defense Advanced Research Projects Agency (Darpa), the development agency of the United States Department of Defense, presented a project where artificial intelligence was used to develop and find the best synthesis methods. The user can input any structure, either known or novel, and then a machine generates thousands or even millions of reaction sequences in order to end up with the final product. Reactions are being ranked and identified based on feasibility, cost, and other factors. Darpa has two ways of doing this. They can apply the expert system, a system based on 60 000 handwritten rules, which is effective but not scalable. Alternatively, they can encode each of the molecules to predict bond changes, using machine learning (much like on molecule predictions). The next step is having a manual help to filter the results and generate a shorter list of top candidates.
There are three fundamental problems in using the machine learning approach as opposed to the expert system. First, the challenges seen in using machine learning, in this case, is the data acquisition. There is missing information and biased reporting due to lacking reports on failed experiments. When it comes to reaction sequences that can be extracted from patents, not all information is going to be reported in the same place.
The second disadvantage is data representation, meaning how this data is presented and explained to a machine in a comprehensive way. The data format needs to be considered and determined — whether the data is presented in formulas, images, features, properties, etc.
The third problem is the exploration space. That space is so much vaster than the information we have available. That raises questions about how to teach a chemistry engine to invent new potential molecules and pathways when we don’t have data on that at all.
There is a model called Molecular Transformer: A Model for Uncertainty-Calibrated Chemical Reaction Prediction which can predict the outcome of a chemical reaction with much higher accuracy than trained chemists, and it will suggest ways to make complex molecules. However, it needs a lot of data and in a very specific text-based format called SMILES (simplified molecular-input line-entry system) that has been data mined from patents. In the end, the preparations to use it for a specific use case might not be worth it from a cost perspective.
3. Organizing knowledge
Artificial intelligence is already used in prior art. There are a few existing and future inventions in that area which will change the current process radically. The first and most basic invention already in use is smarter search. Automated literature reviews is the second step, which we have been working on for the past five years at Iris.ai. We’ve gotten to semi-automation, meaning the search needs human-machine collaboration.
The next frontier that we are working on is identifying specific insights from text. The first step is advanced data extraction and linking, which we have developed in our Extract tool. The PDF to be extracted is sent to the Iris.ai system. This PDF can be a patent, a clinical trial report, a research paper or any other relevant type of scientific content. It can be one simple document at a time, or hundreds or thousands of them in a batch. The Iris.ai engine extracts the text and identifies all the domain specific entities, then locates the tables and extracts the data from rows and columns, and links the data between the text and table. Graphs, figures and other elements go through the same process. Then the engine populates a pre-defined output in a machine readable format; an excel sheet, an integrated lab tool, a database or anywhere else your researchers require.
What’s important in this step is the self-assessment module which communicates to the human researchers how confident the machine is in its results, to give the human guidance on where to do the most rigorous manual verifications.
In the long-run, we expect to see developments in hypothesis extraction from the prior art, knowledge validation based on prior art, and lastly, drawing new conclusions and finding new hypotheses from all of the existing prior arts.
Automating manual tasks vs. rethinking the imaginable
There are two very different mindsets when it comes to applying AI in your organization. You can replace a human process and have a machine do the same activity but faster, for example, in extracting the data. Willingness to invest time and resources is needed, but there is clear ROI and known outcome and benefits. The second mindset is about activities that cannot be done by a human. For example, a machine can identify new potential application areas, meaning you need willingness to invest as well as rethink and re-imagine what’s possible (ROI will be unknown until you try).
Interpretability and explainability
One of the emerging fields in AI worth mentioning is interpretability or explainability. It is not just AI that tells if something will work or not, but explaining why. For example in molecule prediction, AI can predict that certain actions will cause an activity or property because of a specific area in the molecule or combination. As a result, it gives the chemist an immediate indication of how it could be altered if the reaction is unwanted. Similar to the data extraction tool that Iris.ai is working on, where every row and column will come with a machine-created self-assessment with a percentage of certainty.
For the past 18 months, we have been hard at work to create a brand new product offering. We are finally ready to start introducing the details of our upcoming new tools!
First, a bit of background. We have spent the last five years building an award winning AI engine for scientific text understanding. Our engine deals with similarity, causality and compositionality of highly complex academic and scientific texts, and this understanding creates a variety of opportunities for any human with the need to process vast amounts of scientific text.
We started applying this engine in what is likely to be the hardest place: With the academics. We saw how our engine could help students and researchers in the early phase of a new project, where there is a need to perform what is called a “systematic research landscape mapping” – or a full literature review, if you like. We applied the engine to this, building out a suite of tools where the users first Explore broadly, based on a natural language problem statement of 300-500 words – and then Focus down to a precise reading list. We have been able to prove that the Explore tool yields far better results than old school key word based search engines – and that the Focus tool saves researchers up to 78% in their phase of narrowing down, at the same academic accuracy, compared to a manual review.
This is great for academics who absolutely need systematic thoroughness in their reviews. Not so for most industrial researchers: we were asked time and time again whether we “could just give them a quicker answer”.
As our engine is already generalized with a training data set of >18M academic articles and a vocabulary of more than 200,000 words, specializing the core engine is easy enough: For each domain we need a collection of articles from within the domain – about 2,000 of them – or, for some use case, a human made seed ontology to get the process started. Both of these are simple enough – especially the former, as we’ve built the Explore tool exactly for this purpose.
Once the engine is specialized, it also needs to be added to specific tools solving clear problems. Here, we have worked closely with the chemical industry to identify three separate use cases that we are turning into three tools. The tools are all at their core understanding scientific text, but operating at three different levels of granularity.
Discover: mapping out the landscape
At the highest overview level, the Discover tool allows researchers diving into a new area in order to rapidly map out relevant papers, patents and internal documentation related to their problem. The input is a piece of text describing the research focus, and the output is a visual overview over the main topics and highly matching documents. The Discover tool can be connected to any scientific text based content, and as the engine is trained on the specific field, the results are interdisciplinary but highly specific and relevant.
The discover tools deals with unknown unknowns: where you are still in the early stage of a research project and really need a better overview over what you need to know.
Identify: finding the right bits of knowledge
Identify is a much more advanced tool, in the shape of a conversational AI. This means you provide the tool with some starter information about what you are looking for, and the tool asks clarifying questions to narrow down to the precise bits of information. This could be for example finding new application areas for an existing compound, or alternative synthesis procedures. You provide the tool with the chemical name and formula, and the tool builds out a knowledge graph, asking you to build out more details where it is missing them, such as a description of properties or known areas of application. All along you can see what the machine brain is finding and thinking, and the results are presented as highlighted pieces of text in from papers, patents and other documents.
The Identify tool deals with known unknowns: when you know the answer is “out there somewhere” but it is like looking for a needle in a haystack.
Extract: fetching key data from document
Extracting key data from a set of documents is tedious, boring and error prone, but often necessary, for example before going into the lab to recreate experiments done by others. Connecting written descriptions, tables and figures and placing it all in a systematic tabular format is where the Extract tool shines. Two full months of human labor can be done in a matter of minutes, at 90% accuracy. The input is a document (such as a PDF patent) and the output is the data related to the experiment processes, products, results and all their corresponding numbers and units. The data is in a tabular format and can thus be used with Excel, a database or any process tool you are using.
The Extract tool deals with known knowns: They just need to be extracted in the right format, with the right connections, for them to be actionable.
We are very excited to see these tools coming to life together with our chemical industry co-development partners and clients, and would be happy to discuss with potential new partners what we could help you with!
At Iris.ai we have spent the last five years researching and developing an AI Engine for Scientific text understanding. Already successfully deployed in a generalized suite of tools for Academic literature reviews, we believed it was time to see how this engine could be reinforced on one specific domain, and how it could be used to find precise and more spot-on answers for industry researchers. Chemistry was an interesting place to start, for the reasons outlined below, as well as because it is an industry ripe for digital innovation and essential for the sustainable future of our planet.
The interesting thing about chemistry
In 1776, chemist and mechanical engineer James Watt invented the Watt steam engine, which was fundamental to the changes brought by the Industrial Revolution. Ever since – and potentially even before – an understanding of chemistry has been the foundation for our technological development, and there is no reason to believe that this holds any less true for the future. Whether we need more sustainable materials or biodegradable fuel to reduce our carbon emissions, new materials allowing us to travel to space or terraform Mars, novel ways of ensuring that every person on this planet is properly fed or understanding how we can handle an ocean filled with plastic particles, chemistry is going to be absolutely foundational.
What has enabled such a thorough understanding of chemistry pertains to the field’s formalism – the same as for maths and physics. This means structured approaches to unifying language so that any chemist anywhere can talk about anything from the basic elements, via molecular formulas to complex synthesis procedures in the same way. This structured way of communicating with each other has allowed rapid progress in this scientific field.
However, formalism has its downsides: when you simplify a process or a thought process into a unified language, inevitably there will be a loss of information on the way. Much like a compressed image is easier to share and still show the same motive – but is pixelated, so can formalist research results be easier to convey transmitting a general idea of the approach, whilst missing the finer details though. Ideas are compressed to formulas, long research papers compressed to abstracts, novel ideas compressed to a 140 character tweet, detailed lab notes compressed to summaries.
In chemical research, this ‘compression’ has been required because of human limitation – but today, it isn’t required anymore. Computers have already allowed a much broader and larger volume of shared knowledge – which in itself makes absolute formalism tricky. And thanks to advances in AI, we are rapidly approaching a new frontier in chemical research (and beyond).
With new AI advances, machines can help researchers find what other researchers have done, ‘translate’ it into that researchers’ current context, and get a much higher clarity on how and why the solutions or conclusions were reached – without the information loss built into the current process. The machine will have all necessary information as there is no information loss – but only communicate or ‘translate’ the exact relevant pieces between the researchers. This will truly be a new paradigm of chemical research, and we intend to be part of it.
Iris.ai’s first steps into chemistry
We have taken our core engine and reinforced it on chemistry. The interesting thing about that approach is that because the starting point of the general engine is strong, we only need a small collection of research paper in the specialized field, or for some use cases a seed ontology already created by a human, to specialize the tool – which makes it very flexible and re-deployable on many different research fields with similar user needs.
We are already now building out this engine into the first set of tools that will help Chemistry researchers on three different levels:
Discover. When dealing with unknown unknowns, the Discover tool allows interdisciplinary discovery, beyond today’s limiting keyword queries. It fingerprints the description of the researchers’ problem, and maps out all relevant papers and patents they should be reading to get a full overview of the field. The discover tool is especially helpful at the early phase of a new and interdisciplinary project, where it has proven to give researchers a better overview, find more spot on papers and draw better conclusions.
Identify. When the researcher knows the answer is ‘out there somewhere’ but it’s like looking for a needle in a haystack. Known unknowns can be found through this conversational AI that guides the researcher through the information found in millions of documents, asking the right questions to narrow down to exactly the bits of knowledge you need. This knowledge could be finding new application areas for an existing compound, identifying better synthesis procedures or simply identifying the right material for your use case.
Extract. In spite of chemistry being such a formalist field, every researcher writes in their own way. That means when you have a need to extract key data from a document – for example experiment data before going to the lab to recreate them – it takes a lot of valuable researcher time. Our automatic extraction achieves 90% accuracy and perform two months worth of manual labor in a matter of minutes.
At Iris.ai, we are very excited in bringing our AI skills together with some very talented chemical researchers, and see what just might be possible when you bypass the limitations of human formalist language and let an AI understand the context of your words to help advance your research.
The past and the future of chemistry as we know it.
In 1776, chemist and mechanical engineer James Watt invented the Watt steam engine, which was fundamental to the changes brought by the Industrial Revolution. Ever since – and potentially even before – an understanding of chemistry has been the foundation for our technological development, and there is no reason to believe that this holds any less true for the future. Whether we need more sustainable materials or biodegradable fuel to reduce our carbon emissions, new materials allowing us to travel to space or terraform Mars, novel ways of ensuring that every person on this planet is properly fed or understanding how we can handle an ocean filled with plastic particles, chemistry is going to be absolutely foundational.
What has enabled such a thorough understanding of chemistry pertains to the field’s formalism – the same as for maths and physics. This means structured approaches to unifying language so that any chemist anywhere can talk about anything from the basic elements, via molecular formulas to complex synthesis procedures in the same way. This structured way of communicating with each other has allowed rapid progress in this scientific field.
However, formalism has its downsides: when you simplify a process or a thought process into a unified language, inevitably there will be a loss of information on the way. Much like a compressed image is easier to share and still shows the same motive, but is pixelated, so can formalist research results be easier to convey, transmitting a general idea of the approach, whilst missing the finer details. Ideas are compressed to formulas, long research papers compressed to abstracts, novel ideas compressed to a 140 character tweet, detailed lab notes compressed to summaries.
In chemical research, this ‘compression’ has been required because of human limitation – but today, it isn’t required anymore. Computers have already allowed a much broader and larger volume of shared knowledge – which in itself makes absolute formalism tricky. And thanks to advances in AI, we are rapidly approaching a new frontier for research.
With new AI advances, machines can help researchers find what other researchers have done, ‘translate’ it into that researchers’ current context, and get a much higher clarity on how and why the solutions or conclusions were reached – without the information loss built into the current process. The machine will have all the necessary information–as there is no information loss–to communicate or ‘translate’ the exact relevant pieces between the researchers. This will truly be a new paradigm of chemical research (and beyond).
The chemical industry is trying to solve a 21st-century problem with a 20th-century approach
The state of scientific knowledge today is as if we had millions of cities (knowledge nodes) but only small footpaths through the woods to connect them – and no reliable map. However, with recent advances in AI technology, we are now able to build some serious digital highways, connecting all these ideas and people.
Discovering scientific insights about a specific topic is challenging, particularly considering that chemistry is one of the top-five most published fields with over 11 million publications and 307,000 patents. Moreover, the pace at which worldwide scientific knowledge expands is staggering. In 2016 alone, almost 2.2 million scientific articles were published and this output is doubling every nine years. In the process of trying to navigate, extract information from, and understand all this material, simplifications are being made and too much information is lost or missed. This is hampering global progress, and frustrating both the individual researchers trying to wrangle all this information and their R&D managers responsible for the department delivering quality commercially feasible results.
We have reached a point where a researcher will know that the answer they are looking for is likely to be ‘out there somewhere’, but there is no way for them to find it. The reasons for this include:
a) there is not one table in one location where all the information one might need is stored;
b) researchers are no longer able to adhere strictly to the previously helpful formalist rules as interdisciplinarity and creativity is (or should be) the new norm;
c) no-one documents and disseminates information in the exact same way; and, at the end of the day,
d) there is simply too much knowledge for a human researcher to assimilate.
This causes major challenges in finding the right knowledge, whether the answer is a quick and simple one (“what other applications are there for my compound?”) or way more complex (“if we extract the knowledge from these three papers, these ten patents, and this product sheet… doesn’t that mean we have an entirely novel compound?”).
Chemical companies need to:
a) find ways to utilise their core competencies and existing knowledge to generate new revenue,
b) reduce the risk of lab experiments failing by having as much upfront information as possible, and
c) make their R&D process as cost-efficient as possible without compromising quality.
The best way to go about the first two challenges is leveraging existing scientific literature, but unfortunately, that is not possible today while at the same time achieving the latter.
Chemical companies’ R&D departments today are absolutely vital to the companies’ survival and ongoing success, but they are at the same time seen as a non-revenue generating “burden”: Necessary, but expensive. Very expensive.
Chemical companies’ R&D departments today are absolutely vital to the companies’ survival and ongoing success, but they are at the same time seen as a non-revenue generating “burden”: Necessary, but expensive. Very expensive. R&D managers are under pressure to deliver more results, faster, but because of the overwhelming amount of information, it is becoming increasingly difficult. At the same time, their most valuable R&D assets are their research staff, to whom searching through thousands of documents to try to find answers is just an annoying and tedious burden, far removed from the real fun work that happens in the lab. And the less the researcher reads in advance, the higher the chances are their lab experiments may fail, wasting their time and the company’s valuable budget.
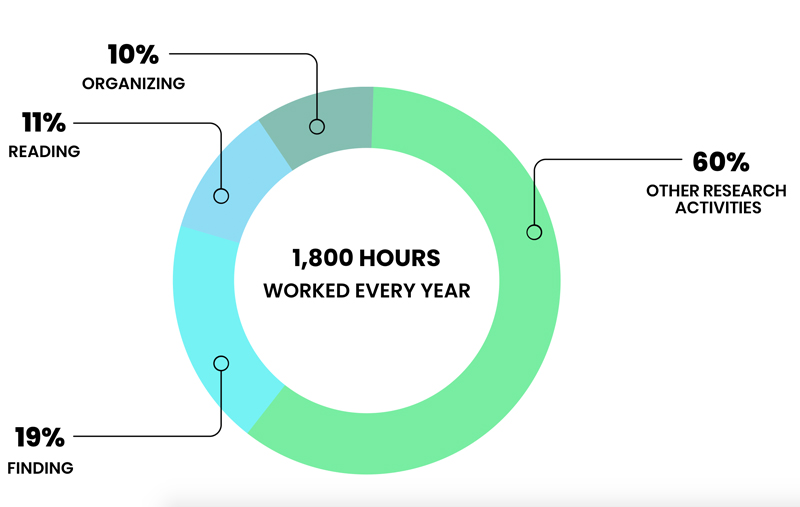
Out of an average of 1,800 hours worked every year, studies show that about 40% of a chemistry R&D researcher’s time is currently spent between finding (19%), reading (11%) and organizing (10%) existing literature. This represents a massive inefficiency.
To remain competitive and grow their market share, chemical companies need to constantly ask themselves the questions listed below, and efficiently find their answers from existing literature (something not fully possible today, based on the current state of affairs, including the productized available technology):
What are new uses for an existing compound?
How can we change the properties of an existing material?
What other synthesis pathways will improve our existing manufacturing process?
What compounds with specific properties can be used as substitutes in an existing application area?
What new chemical substances can we create by combining known compounds, and thus a new market?
Of all of the above questions, what approaches are more sustainable, as we are under continued pressure to reduce our environmental footprint?
The only way for industrial chemists to potentially find answers is relying on limiting keyword-based search engines, summarized findings that ‘everyone’ has access to and following key researchers on social media channels to see what they are up to. After that, no matter how the papers are found, they still need to manually screen and review existing chemical literature one paper at a time. But as we have shown above, this is a very challenging task with very slim chances of finding what is needed. And even if they should be diligent and have a large enough team to be able to stay on top of existing literature – they can not also have time to crunch the findings, test the knowledge, validate the hypotheses in the lab and then publish the results as well. This means that, based on the current state of existing knowledge management solutions, there is very little time for actual innovation. Chemists then have no other alternative, but to rely on their own experience, limited knowledge, rules of thumb, outdated tools and the occasional dumb luck. Moreover, ‘blind’ trial and error leads to repeatable, mundane and time-consuming tasks, ending in unpredictable results – until hopefully a solution is found, although with low confidence it was the best solution or a good use of time.
Innovate or die must be adopted as the key mantra by the chemical sector if those companies want to remain competitive.
The chemical industry is today trying to solve a 21st Century problem (increased speed-to-market, lower product margins and cut-throat global competition amidst an overload of information) with a 20th-century approach (slow, outmoded and error-prone guesswork).
Chemical companies are coming under increased pressure to get smarter in the current wave of digitization, amidst new technological challenges, shrinking product life cycles and the rush to commoditize products. They simply need to increase the pace of innovation.
Innovate or die must be adopted as the key mantra by the chemical sector if those companies want to remain competitive. This involves embracing innovative ways to research and develop new commercial products.