What made you realize that you needed something like Iris.ai?
As a researcher and an educator, one of my interests is exploring useful tools to help researchers to speed up their research process. In 2018, I discovered powerful Explore & Focus tools from Iris.ai. The Explore tool is my favorite and it’s always my first choice when I recommend research tools to my students. The Explore & Focus tools help me discover more papers that I may have missed.
Why did you choose to use our tools over other options?
Iris.ai was the first AI tool that I tried out in 2018. Back then there weren’t many applications for research discovery and Iris.ai definitely stood out to me. The company’s vision highly resonates with me.
How did you find out about Iris.ai Researcher Workspace?
I have been an Iris.ai follower since 2018, and I have always kept up with the news. I was lucky enough to be offered access to the Researcher Workspace, before its release for individual subscriptions.
Could you tell me about a project where you used the Researcher Workspace for?
I am trying out a project named Collaborative Learning that I used for my Grant Application. Iris.ai assisted me in identifying more related papers for my literature review.
Can you talk us through the process of how you used the Researcher Workspace for that project?
I use the Researcher Workspace in two ways. The first way I’m using the Explore tool is by inputting the link to one of my relevant papers. Then, Iris.ai provides me with more quality papers that are interesting for my topic. The second way I’m using the Researcher Workspace is by importing articles from Mendeley. I export the references as CSV/RIS and then import them into the RW. After that I apply Analyze and Filter tools to help me narrow down the list of articles to make it more specific and closer to my research needs.
What challenges did you experience that Iris.ai helped you overcome?
The biggest challenge that I have experienced is the fear of missing important papers. Iris.ai’s Explore tool uses synonyms and concepts instead of simple keywords. Therefore, I was able to discover articles on my topic that were using different phrases than I did.
Would you recommend the Researcher Workspace to other people?
Of course, I will! I regularly hold workshops for my students in Malaysia where I present the Iris.ai tools. I am very excited for the development of the Researcher Workspace and I can’t wait until it will be open for individual users.
What made you realize that you needed something like Iris.ai?
I realized my literature searches were not dynamic enough, and I was invariably missing important recent work in the hydrologic sciences, especially as that work spans chemical, health, and remote sensing literature spheres in addition to the physical hydrologic journals.
How did you find out about Iris.ai Researcher Workspace?
I was searching online for smart platforms and applications that could help me with my literature searchers and that’s how I came across the Researcher Workspace.
Could you tell me about a project where you used Iris.ai for?
I used the Researcher Workspacde to develop a background context for a study on emerging contaminant transport from groundwater to surface water.
Can you talk us through the process of how you used Iris.ai for that project?
I used Iris.ai tools to search through the Core database and my personal collection of article PDFs using the abstract from a paper that was well aligned with my research themes. Then I used the visual map created by the Explore tool to better understand how the main themes of that paper were connected to other work. After that I accessed specific papers that were rated as highly relevant and connected to at least two prominent themes and read them for additional detail.
What challenges did you experience that Iris.ai helped you overcome?
I found several highly relevant contaminant fate and transport papers that occurred in chemical sciences journals I do not typically track, and otherwise would have missed them. Also, Iris.ai was helpful in finding related research at the global scale, not just North America and Europe where many hydrology journals are focused.
Would you recommend the Researcher Workspace to other people and would you consider using it later on with your new job?
Yes, I have already recommended it to my colleagues.
I’m from the Seattle, Washington area in the United States and have been a PhD student at the University of Washington for about the last three and a half years. I actually just graduated a couple of days ago. So technically I can’t be considered a student anymore. I have a degree in Epidemiology and my primary research focus has been on placental Epigenetics – it’s a very niche subject area.
How did you get to know Iris.ai Researcher Workspace?
I got connected with Iris.ai through a side job. Back in April last year I was working for a small startup in Seattle and they were interested in knowledge acquisition and the ways to do it effectively and efficiently. The company received some communication from Iris.ai and it sparked their interest. I joined some of the calls between Iris.ai and the company. And while they didn’t end up pursuing it, I decided to try it out for my studies.
Could you tell me about a project you used Iris.ai for?
The primary project that I was using Iris.ai for was my dissertation on placental Epigenetics. I was trying to find new and tangential references for unusual connections with long non coding RNAs. It’s a very niche topic and there’s not a lot of information on them in the way that I study them, but Iris.ai helped me find great articles.
I had a list of the core papers and I used the references to branch out from there. I used the Explore tool to see what other relevant papers were out there. Then I picked out the relevant ones and followed up with another search. So Iris.ai helped me to be very efficient at finding all these potentially relevant articles. Additionally, using Explore and Analyze and looking at concepts and just the content in the search gave me more insight into what to look for first and what to approach in my normal searches, for example using Google Scholar.
What challenges did you experience using the Researcher Workspace?
Sometimes the articles you find are an important reference, but it’s on the edge of what you understand, and so that itself is a fun challenge. It’s just a matter of finding things that you need. Iris.ai does a good job of locating them in the first place, but then you gotta be the one to actually interpret it.
Why did you choose Iris.ai over other options?
I have not necessarily looked at all that many other options in terms of search platforms. I have seen some but they were not reasonably priced for a PhD student. I also haven’t gotten on the Chat GPT train or anything along those lines. I’m a bit more analog. I like to read my own papers. Iris.ai was interesting and very effective in what I needed to do, and it plugged in pretty well with my information infrastructure and so I haven’t really needed to go looking for something else.
Would you recommend the Researcher Workspace to other people and would you consider using it later on with your new job?
Absolutely yes – to both questions! I would certainly recommend it in terms of just how helpful it was for my PhD and I would totally recommend it to other students.
In today’s article we will continue on our Tech Deep Dive series. This time we will be talking about automatic summarization. We will compare extractive vs. abstractive summarization, what are the challenges and of course we will explain how our abstractive summarization model works. Do you enjoy this series and want to be notified about the new articles? Subscribe to our newsletter!
Most of the summarizations available on the market are extractive. Extractive summarization combines existing sentences without any alterations to create a summary. Abstractive summarization, on the other hand, involves text generation. Essentially, in the abstractive summarization the machine writes its own sentences.
Challenges
Generally the abstractive summarization is easier to read and more like human written. On the other hand, since the extractive summarization only copy and pastes the sentences without any changes the summary will contain less factual error. Depending on the probability model that the machine uses, the abstractive summarization can put the information learned from different sentences into one and therefore create a factual error called mixed context hallucinations. This is also what we are experiencing with ChatGPT – the machine presents the facts learned from different sources without disambiguating the context. As a result, the machine can piece together the sentences that would sound correct, because of the text generation model, but the information itself can create factual errors.
Above you can see the example of a ChatGPT hallucination. When asked if vanadium is a good conductor of heat, the machine answered “yes”. However, vanadium is known to be a “rule-breaker” among these types of metals. Even though essentially, the law states that good conductors of electricity are also good conductors of heat, vanadium counteracts this law. Vanadium dioxide is a good conductor of electricity but not of heat.
With the rapid advancements of generative AI we need to develop models to ensure the factuality of the generated text and create a metric to assess the factuality.
Why did we choose abstractive summarization
Extractive summarization is more rigid and due to just gluing together exact sentences taken from the article the text might read awkward. Text generation in abstractive summarization imitates better human writing style and is easier to read. Abstractive summary is more coherent and concise. The text generation used in the summarization model gives us more flexibility in the future to apply it to other cases.
How did we get here
To train our first summarization model we used a big dataset of patents – 1.3 mln patents. After that we realized that summaries generated on scientific publications were written very differently. That is because both of these types of documents use different writing styles. Therefore, we decided to train another model on scientific articles, which is now included in The Researcher Workspace’s Summary tool. For the training on scientific publications we have curated the dataset of 1 mln articles. Having the summarization model trained on scientific publication makes the summaries sound more human written because of the writing style used in the articles, as opposed to patents.
So how does it really work
Iris.ai Summarize tool can summarize, as the name suggests, scientific articles. It can summarize either abstract or full-text of one or multiple articles.
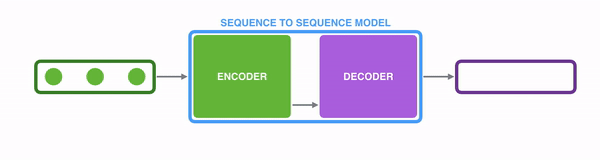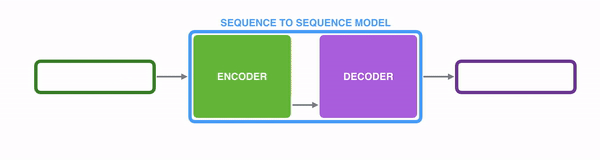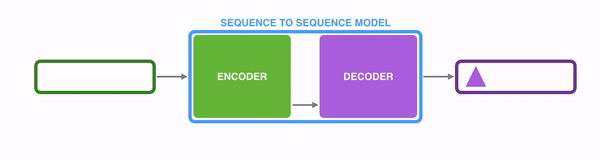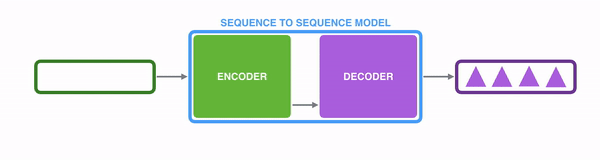
The single document summarization adopts an encoder-decoder architecture to encode the input fulltext and decode the output on the fly to abstractively generate a summary. To start off the process the user gives the machine a text to summarize. Then the machine reads and analyzes it using an attention score. Attention score is based on the material used in training the machine. It analyzes the relationship of words and phrases and the writing style. Then using this experience it writes down the first word. To continue the sentence the machine uses the probability and generates each next word until the end of the sentence. The process is repeated until the full summarization is done.
The single document summarization and multi document summarization have the same base, but the multi document summarization has an additional layer.
To create a multi document summary we scan all the documents and based on their content we rank the sentences on the importance in the article. Once the sentences are ranked, we choose the most important once across all articles and stitch them together to form a new text. Then we use a single document summarization process to create an abstractive summary.
The summary can create some biases. For example if the user chose five articles and one article is significantly different then the rest it can create a confusion to the summarization model. This happens because the contribution from the other articles will create a larger probability for the text generation for the summary and therefore create a bias toward the article that had different conclusions. As a result the content from the article that is very different from the others may not be well summarized. Hence when creating a multi document summary it is important to choose the articles based on a similar topic.
In Iris.ai Summarization tool we use the evaluation model that can classify whether the fact presented in the summary is correct or not. The model is still in the experimental stage and we are still trying to regulate the factual error that is generated by the machines. To fight with the factuality issue of abstractive summarization we are building a knowledge graph to help us generate the text that is more factually correct.
Future steps
We have already made steps towards improving our summarization model. Firstly we want to train the model with knowledge graphs to improve the factuality and the assessment so the user can understand and verify the factuality of the generated summary. Another point on our roadmap is to create topic tailored summarization. The goal is for users to be able to provide context e.g. specific entity (drug, material, etc.) and the machine will apply higher importance to the information about said entity as opposed to usually objectively assessing which information is central to the whole article. Lastly, we want to develop audience tailored summarization. Language of the generated summary would adjust depending on the type of audience and their level of knowledge in the research field. The machine could use simpler language for the students and more advanced and for experienced professors or field professionals.
Today we’re coming to you with the next article in our Tech Deep Dive series! In this series we explain the technology behind our tools. In our previous articles we wrote about “Extraction of table data (and why it’s difficult)” and “Parsing, entity extractions and variables linking”. This is the 3rd and last part of unraveling the Extract tool, where we will take a closer look at how the entities are being linked to the Output Data Layout and what other information the client receives after the extraction is done. If you are interested, subscribe to our newsletter to be the first one to notify whenever a new blog post is published.
To summarize, during the extraction process we have located the tables in the PDF documents and extracted the table captions and the data inside it. Then we have extracted the metadata and entities and quantities from text. Lastly, we have put the data points the clients want to extract into a spreadsheet we call Output Data Layout Now it’s time to put it all together!
Grouping entities into products
The first stage of the process is grouping entities in what we call a product. One row in ODL is one product. In the steel industry a product would be a material produced and in pharma – the tested drug. Another part is linking the data in the table rows to the correct products described in the text.
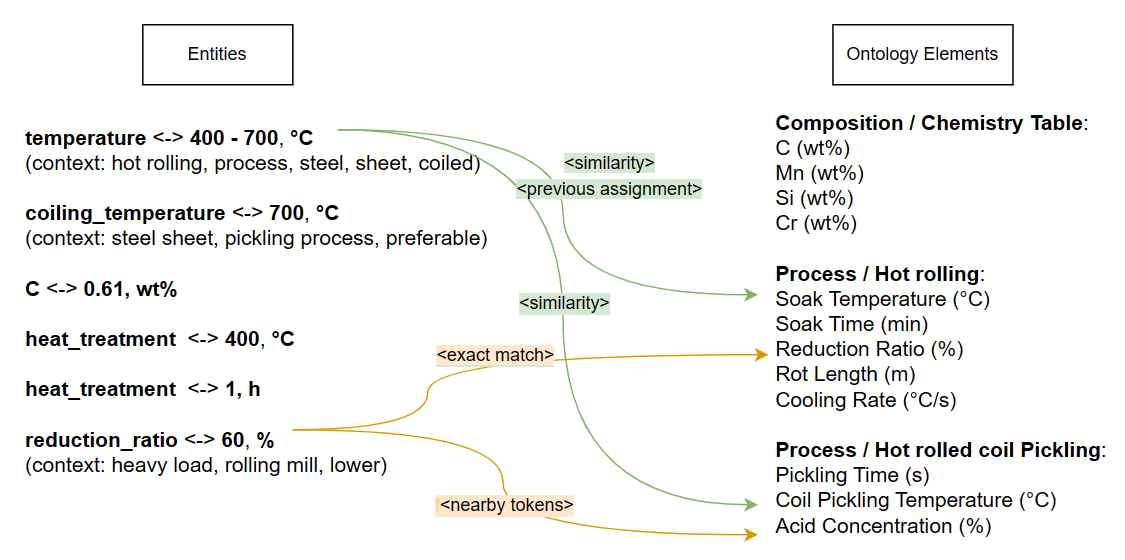
Linking entities to ontology elements
Now we have a bunch of entities – entities from text and entities from the table. At this point they are not connected to the Output Data Layout. The first step is to create connections between extracted entities and ODL elements based on known features that could help our Assignment Solver Model to decide which entity should go to which ODL element. Examples of such features are when the entity and the element have the same units (e.g. °C connected to temperature), are used in a similar context, appear in near proximities in texts, etc. Each established connection is rated based on various characteristics and then we use the ASM model trained on the connections that selects the best option. Once we are done with extraction the choices are stored in a graph database so they can help us improve the ASM going forward. Unfortunately, it’s not as simple as it seems. Sometimes we have entities that could be connected to multiple ODL elements and we consider that a candidate and we want to choose the best candidate, of course. But this entity could be a candidate for another element as well and at the end it should be assigned to only one ODL element (and one product). The problem begins to be quite complex – since every time you do an assignment this entity could not be a candidate for another ODL element anymore. Therefore we use advanced algorithms on top of the ASM to optimize the search for optimal assignment in this multidimensional problem.
Reinforcement
The engine can be reinforced on client’s industrial domain so it will more accurately connect the right data. We teach the machine the industry language: the terminology, the format of papers and patents, abbreviations, units etc. We need very few examples to be able to do that. As little as 5-10-20 are enough since we use our other tools to find similar documents to grow the dataset (as the bigger the corpus, the better the results). In this way the machine becomes better at understanding the specifics in the industry and understands the connections between entities and ontology better.
Final results
The last stage is exporting the results in ODL format (usually tabular format like Excel or other desired by client format). We also generate debug information – it helps clients understand what is going on in different stages. It contains a folder with few files – highlighted PDFs with entities that we extracted and highlighted tables, .csv file with data from tables in tabular format and JSON files that contain valuable information to track the results from every stage. Additionally, in the result file there is a separate spreadsheet with confidence for each extracted data.
Verifying data accuracy
To verify the accuracy of the results we use precision and recall as well as a self assessment module. For the precision and recall we compare the annotated results from the client to the results Iris.ai provided. Recall measures if we extracted all data the client requested and precision measures how many of them have been extracted correctly. The self assessment module rates how confident the machine is through each stage of the extraction. The confidence is measured in number and is included in the ODL.
Summary
👉 The data extraction process is complicated and includes multiple processes: table data extraction, metadata extraction, extracting entities and qualities and connecting them to ontology elements.
👉 Table data extraction is especially difficult due to PDF formatting and vast variety of types of tables.
👉 The client chooses what data points need to be extracted by creating an Output Data Layout.
👉 The Iris.ai machine can be reinforced on specific industry to provide more accurate results.
Welcome to the second article in the Tech Deep Dive series! In this series we take a closer look at the technology behind our tools. This article is the continuation of explaining the Extract tool. Read the first part “Extraction of table data (and why it’s difficult)”, where we talk about extracting the data from the tables. In this blog post, we will walk you through the process of text parsing, entity extractions and variables linking. If you like this series and want to be notified about the new articles, subscribe to our newsletter.
One part of the extraction process is table data extraction, the other is text extraction. We convert the documents, through an external library, from PDF format to .xml and then to raw text. After that we refine and structure the extracted text into useful information to work with. Next step for text extraction is meta info extraction – the information about the paper itself. In the scientific articles it would be the title, authors, date of publishing and abstract. In case of patents these are: patent number, date filling, date of publication, inventors etc. For that we use pattern recognition techniques to spot the exact location of this information in the extracted text.
So now we have information from tables with specified rows and columns, text and metadata. Further we will focus on extracting key entities of interest.
Extracting entities and quantities
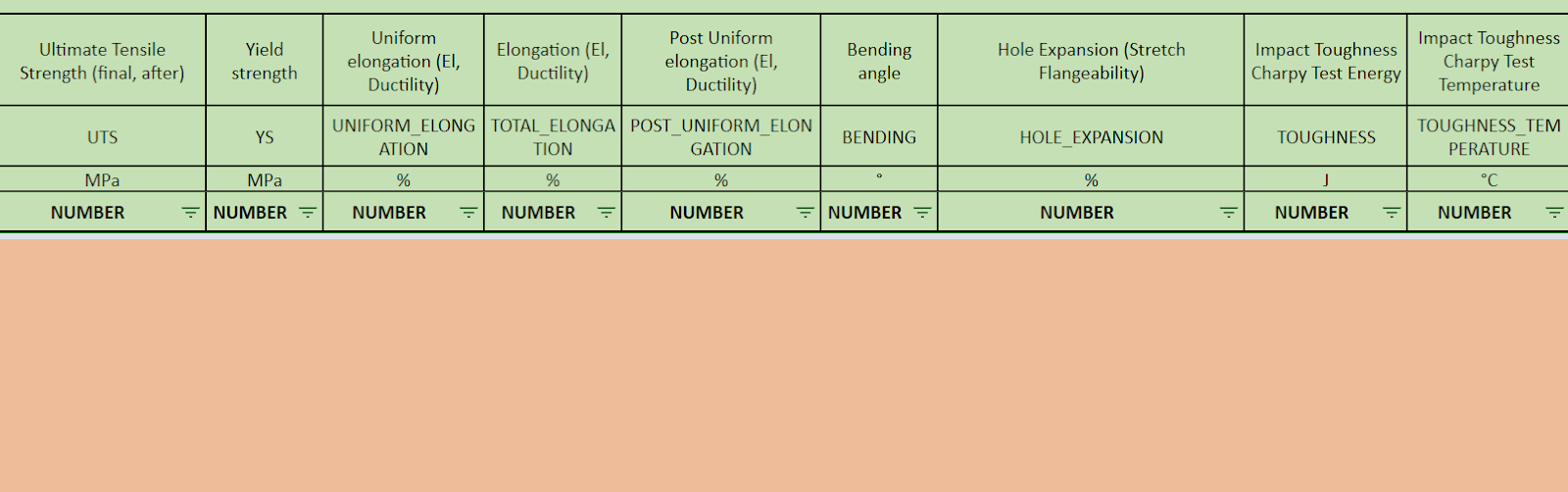
Iris.ai identifies all entities of interest (e.g. temperature) by modeling the text information profile. Then it extracts the quantities – numbers with units (400 °C) and links them together calling each such entity – quantified entity. The quantities can also be defined as a range or value comparison. Besides the name of the entity we also extract the context around it (e.g. boiling temperature” or “manufacturing process) to be able to link those entities to user defined requirements (our clients provide that in the form of an output data layout).
The tables go through the same process, where the header of the column is the name of the entity and the quantity is the value in the cell.
Output data layout
To continue with the extraction our clients need to specify the information they are interested in. Output data layout (ODL) is a simple spreadsheet with specified entities that need to be extracted, alongside with possible supplementary requirements such as the units the entity should be measured in, etc. Such entities could be chemical compounds, process variables, etc. It’s worth mentioning that the Iris.ai engine understands all chemical compounds and could find them even within abbreviations. Moreover, the machine is able to convert the units to the one specified in the ODL. For example all feet, inches, meters and millimeters will be converted to centimeters.
Next Steps
The next step is linking entities to ontology and reinforcement, which you will read about in the next blog post!
We are starting a new blog series! Here is the Tech Deep Dive, where we explain the technology behind our tools. In this first post of the series we will take a closer look at the table data extraction (which is a part of the Extract tool). Our next blog post in a series will explain the rest of the process in the Extract tool – text linking and grouping of data – so subscribe to our newsletter to be the first one to notify!
The table data extraction is a multistage process and each of the stages has its own challenges. At Iris.ai, we split table data extraction into three downstream tasks – table location, table caption linking, table structure and data extraction.
PDFs are human readable
PDF documents are human readable, not machine readable. PDF is a format that allows humans to view the document exactly the same on different programs. This is because the text is actually linked to an image that is displayed the same way. This format was specifically created to universally show information to humans. The PDF document doesn’t have the information on where the tables are exactly, what are the rows and columns – humans can easily see it, but the machine doesn’t!
Locating the tables
To locate the tables in the PDF documents, Iris.ai is using an object detection model. Object detection is a computer vision technique that allows us to identify and locate objects in an image or video. It’s the same model that tells you that there is a dog in the photo. Our machine is trained to detect the rectangles with equally spaced data inside. We input the generated image to the object detection model and it returns the tables’ location paired with the confidence level.
Table caption extraction
The next step is to extract the table captions. The machine does not know which caption is assigned to each table, therefore we extract all possible captions and link them to all possible table locations. Then we choose the right one based on the probability and distance to the table. We also match continuation tables with the original tables.
Table data extraction
The last part is the actual extraction of table data. And it’s more complicated than it looks! To summarize, we located the tables, we know where they are and we know the name of the tables. Now we need to split the data into rows and columns.
We use several algorithms to solve this problem. We use an image-based algorithm to use the visual information for cells split, a statistical algorithm to fill in the missing visual information and a graph-based approach to extract the full table structure. One of the algorithms we are using reads the information in the PDF about the lines dividing the cells so based on that we can actually divide the table in rows and columns. And that’s it! Easy, right? Well, sometimes the PDF doesn’t contain the information about the lines or sometimes the tables do not have lines between the columns, so we need to use a different algorithm that reconstructs the missing lines. The third algorithm categorizes the headers and labels (row names) and extracts the full table structure which allows us to have the table data extracted and structured as in the document.
So why is table data extraction difficult?
Table data is an extremely important part of the data extraction process. Most of the time it’s in the tables where you can find the key information.
The table data extraction is a multistage problem and each stage is difficult on its own. In the first stage of locating the tables in PDFs, the object detection model had to be trained specifically to recognize tables. The training is a laborious and time-consuming process.
Another issue we had to combat is understanding the data – extracting the rows and columns. There are many approaches in the literature to deal with that – advanced neural networks, graph based approaches, rule based approaches etc. – but very few of them actually present good results.
Moreover, if you’ve read scientific papers then you probably noticed – there are a lot of different types of tables. Some tables have lines between rows and columns, some don’t. Some columns are closer together than others. Some tables are bigger and some are smaller. Some tables have more rows and columns and some have less. Sometimes there are two different tables next to each other on the same page. Sometimes the table continues on the next page. That diversity makes it more difficult to extract the data.
Lastly, it’s challenging to find the right balance between the size of the model and the performance. Table data extraction models are big and take a long time, but at Iris.ai we strive to keep up the performance on a good level and provide results fast.
Next steps
After table data extraction, Iris.ai extracts the text and metadata and then connects it to the ODL (Output Data Layout) which you will read about in our next Tech Deep Dive blog post!
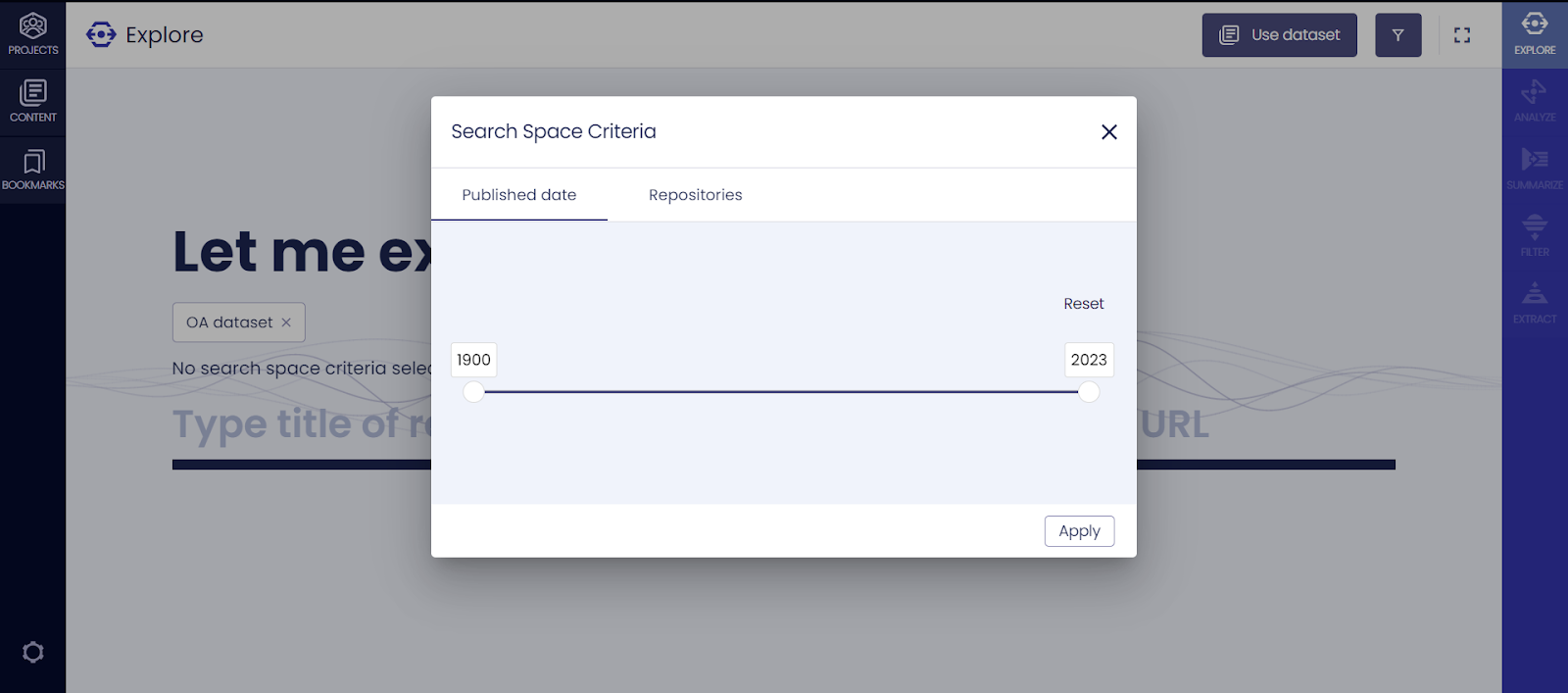
We added additional filters to the Explore tool. Now you can filter your search results before starting the search. From the Explore tool page you can choose which datasets you want to search within and restrict the search by the publishing date or repositories.
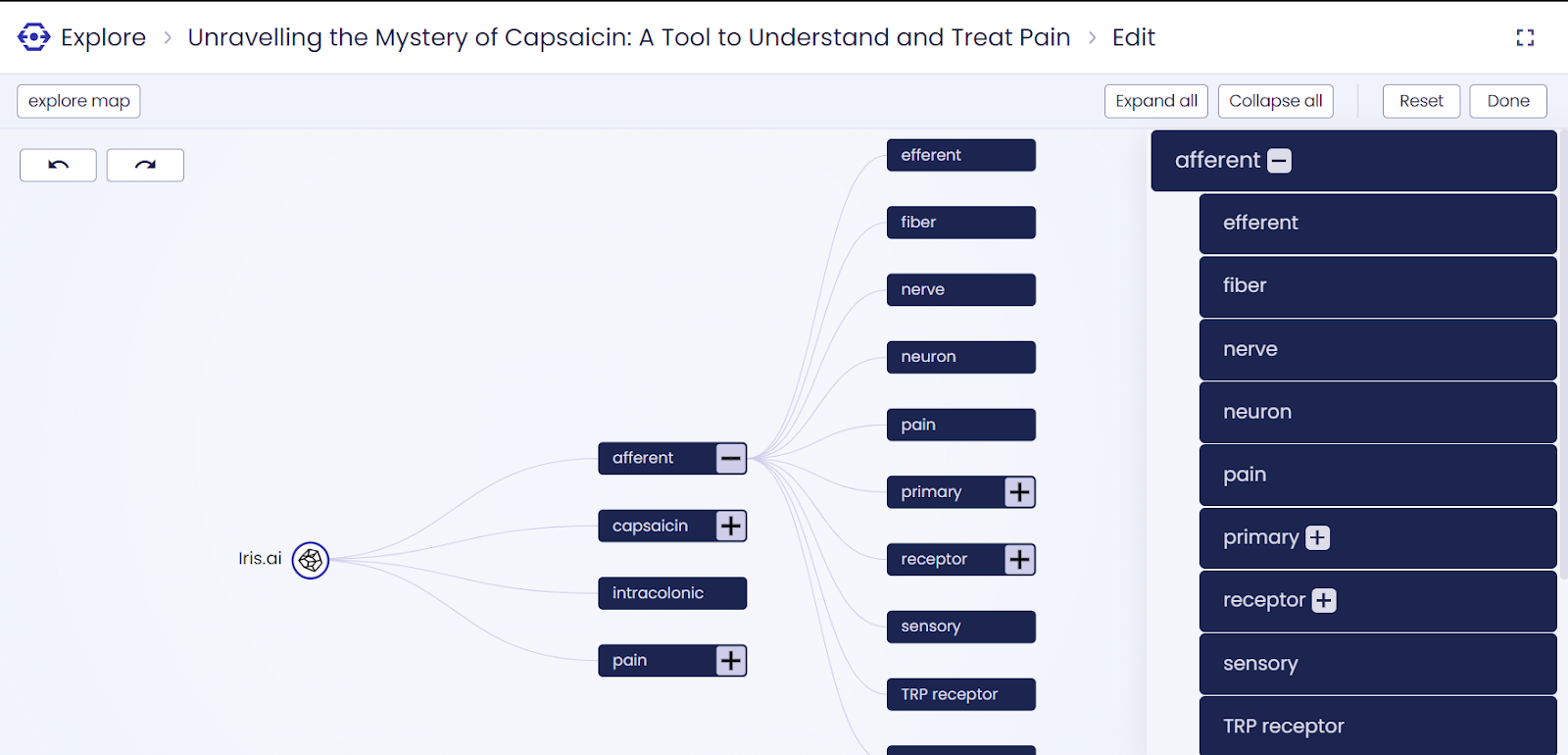
Fork a map
“Fork a map” allows you to edit a copy of the map by editing the structure of the fingerprint. You can expand all concepts of the map to get a better overview. You can merge and move concepts around to change it as it suits you the most, organize the map and get better control of the content.
Relevant article highlighting
Another useful feature is marking articles as relevant. If you mark the article as relevant in the map it will get highlighted – the same goes for highlighting in the dataset. So it’s easier to find it.
User Profile
Now you can edit your information in the user profile.
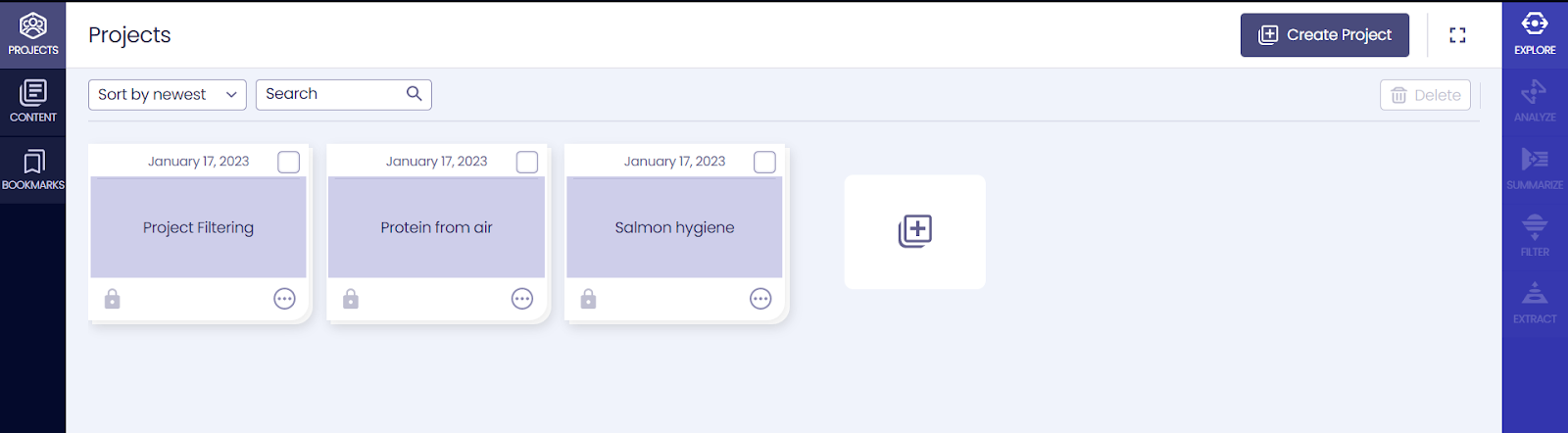
Projects
We saved the best for last! The newest version of the RW has project space implemented. “Projects” is a collaborative space for your organization, where you can work together.
Keep an eye out for the next product announcement, the Researcher Workspace 1.0, which is coming out very very soon!
As broadly announced this week, we are among the latest batch of companies to receive the EIC Accelerator Blended finance – with a €2,4M grant and up to €12M in investments from the European Innovation Council and the European Investment Grant.
It is the flagship startup funding program from the EIC, and it is incredibly competitive, with around 2% of applicants historically being successful. In our round, around 1000 companies made it through Step 1 and were invited to submit a full application in Step 2. About 250 companies were subsequently invited to the interview round of Step 3, and finally we were among the 78 companies offered funding.
For the three co-founders, this achievement is immense – and very meaningful. We wanted to shed some light on what it all means to us.
Firstly – and obviously – it means that we have secured stable operations of the company for the two year period which the grant money is for. It also means a radical boost in our ability to close our next larger funding round to scale our growth, with the EIB as a co-investor with up to €12M.
It means of course great validation of our hard work, the products developed, the company we’ve built, the team around us, our client relationships and the large ambitious impact vision we’ve always strived towards.
It means a great validation also of both the quality and the importance of the research work we have put into the last seven years. It has not always been obvious to the people around us with opinions why we should have such a large research team in such a small, low-funded company. But here we are, at the forefront of AI, more specifically NLP for Science, and all the hard work is paying off.
It means that the company in some sense finally has a home. We started out as co-founders in separate countries; we would never all live in the same place. We hired the best talent where we could find them. And again and again, we met the uncomfortable reality: The European Union is not quite made for that. We weren’t quite Norwegian enough for some Norwegian funding programs; not London-based enough for some UK VCs; not quite close enough for American investors with their post code mentality. Yet we insisted: we are cross-European. We are European. The EIC sees beyond a collection of national markets with national interests. So this funding, to us, validates that we do have a home, and it’s Europe. All of it.
It means that from a global perspective, we are in fact a unique European player who can and will have a role to play in the race for safe, ethical, science backed and factual AI development and application – and a viable competitor to companies in large countries.
It means that when we set out to start this company, it was with a clear impact vision and massive visionary ambitions. We set out to build the world’s first interdisciplinary AI Researcher, and we are still on that path. With the funding from the EIC Accelerator, we finally can match that ambition with the resources it requires.
Some time in 2022, when we had hit quite a rough patch – but we had decided to keep pushing forward, still believing that success was within reach – one of our investors sent us this quote:
Nothing in this world can take the place of persistence. Talent will not; nothing is more common than unsuccessful men with talent. Genius will not; unrewarded genius is almost a proverb. Education will not; the world is full of educated derelicts. Persistence and determination alone are omnipotent. The slogan Press On! has solved and always will solve the problems of the human race.
Calvin Coolidge
So receiving the EIC Accelerator means most of all that our insistence, persistence, and at times stubbornness (bordering on insanity?) – all in the name of making a positive impact on the world of science – was worth it.
The European Commission judges identified Iris.ai as having the potential to support European scientific research and AI development against a growing competitive landscape coming from the US and China
London – 11 January 2023– Iris.ai, provider of a world-leading and award-winning AI engine for scientific text understanding, has been selected by the European Innovation Council to receive €2.4 million of funding in grants and up to €12M in equity investments from the 2022 EIC Fund. Iris.ai was one of just 15% of startups chosen with a female CEO and amongst only 78 successful companies from over 1,000 qualified candidates in a highly competitive selection process.
The European Innovation Council (EIC) is a flagship European program to identify, develop, and scale up breakthrough technologies. In its third year as a full-fledged EU fund, the EIC has a budget of €470 million to fund the most promising technologies across Europe and support European growth.
Iris.ai solves a major problem for researchers – that of the overwhelming volume of research being published. Finding relevant research is like finding a needle in a haystack, and as a result, researchers in both academia and industry are missing relevant published papers that could advance their knowledge or are simply wasting time reading irrelevant research. Iris.ai cuts the time required to carry out scientific research by using AI language models to categorize, navigate, summarize and systematize data from academic papers, patents and all other technical or research documentations. It’s already being used by hundreds of universities and companies – including Fortune 500 steelmaker ArcelorMittal – to eliminate the weeks and months spent manually wading through patents and research.
Iris.ai’ technology has the potential to enable unprecedented breakthroughs in European research through interdisciplinary scientific discovery against growing competition from the US and China. The EIC Jury responsible for reviewing Iris.ai’s application commented: “A strong AI/ML European player is of utmost importance for the EU, given the evident progress in US and Chinese-driven AI developments and the potential biases that could therefore be implemented in the algorithms.”
Iris.ai will use the investment for its core mission: making scientific research more actionable. As a fully horizontal platform, this funding will assist the company in accelerating interdisciplinary research across every field, mapping out the vast amount of research available and helping to broaden researchers’ understanding beyond their specific domains.
The EIC Jury concluded: “We believe that Iris.ai has huge potential, with the investment enabling them to benefit from ‘the horizontal’ competitive advantages of the product and expand into other market segments in the mid and longer term.”
Anita Schjøll Abildgaard, CEO and Co-founder of Iris.ai, commented, “When Iris.ai was founded in 2015, few people had heard of language models. Since then, the AI ecosystem has grown exponentially, and the concept of language models is common knowledge.
“However, the current generation of large language models – including ChatGPT – don’t work for science today. They hallucinate, generate mistruths, and misunderstand scientific text due to a lack of domain-specific knowledge. What we’re doing differently is we are working on factuality validation, and injection of externally validated knowledge – creating a trustworthy system that can be relied upon for analyzing scientific research. Our research efforts are considerable, compared to other startups in our field.
“Together with my two brilliant co-founders Victor Botev and Jacobo Elosua, we are delighted to be selected for the European Innovation Council Accelerator funding. It will allow us to ramp up the development of our technology and achieve our goal of building a complete AI researcher – AI tools and applications which allow humans to make sense of the totality of the world’s scientific knowledge.”






")




")

")




")


")