")
Tech Deep Dive: Extractive vs. abstractive summaries and how machines write them
In today’s article we will continue on our Tech Deep Dive series. This time we will be talking about automatic summarization. We will compare extractive vs. abstractive summarization, what are the challenges and of course we will explain how our abstractive summarization model works. Do you enjoy this series and want to be notified about the new articles? Subscribe to our newsletter!

Extractive vs. abstractive summary
Most of the summarizations available on the market are extractive. Extractive summarization combines existing sentences without any alterations to create a summary. Abstractive summarization, on the other hand, involves text generation. Essentially, in the abstractive summarization the machine writes its own sentences.
Challenges
Generally the abstractive summarization is easier to read and more like human written. On the other hand, since the extractive summarization only copy and pastes the sentences without any changes the summary will contain less factual error. Depending on the probability model that the machine uses, the abstractive summarization can put the information learned from different sentences into one and therefore create a factual error called mixed context hallucinations. This is also what we are experiencing with ChatGPT – the machine presents the facts learned from different sources without disambiguating the context. As a result, the machine can piece together the sentences that would sound correct, because of the text generation model, but the information itself can create factual errors.

Above you can see the example of a ChatGPT hallucination. When asked if vanadium is a good conductor of heat, the machine answered “yes”. However, vanadium is known to be a “rule-breaker” among these types of metals. Even though essentially, the law states that good conductors of electricity are also good conductors of heat, vanadium counteracts this law. Vanadium dioxide is a good conductor of electricity but not of heat.
With the rapid advancements of generative AI we need to develop models to ensure the factuality of the generated text and create a metric to assess the factuality.
Why did we choose abstractive summarization
Extractive summarization is more rigid and due to just gluing together exact sentences taken from the article the text might read awkward. Text generation in abstractive summarization imitates better human writing style and is easier to read. Abstractive summary is more coherent and concise. The text generation used in the summarization model gives us more flexibility in the future to apply it to other cases.
How did we get here
To train our first summarization model we used a big dataset of patents – 1.3 mln patents. After that we realized that summaries generated on scientific publications were written very differently. That is because both of these types of documents use different writing styles. Therefore, we decided to train another model on scientific articles, which is now included in The Researcher Workspace’s Summary tool. For the training on scientific publications we have curated the dataset of 1 mln articles. Having the summarization model trained on scientific publication makes the summaries sound more human written because of the writing style used in the articles, as opposed to patents.
So how does it really work
Iris.ai Summarize tool can summarize, as the name suggests, scientific articles. It can summarize either abstract or full-text of one or multiple articles.
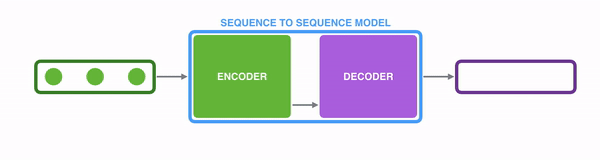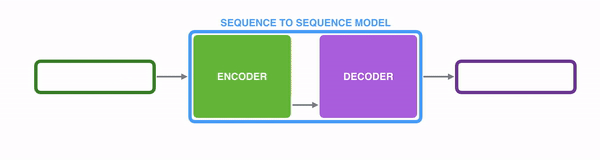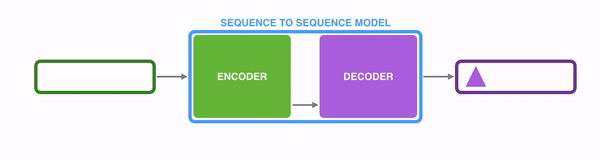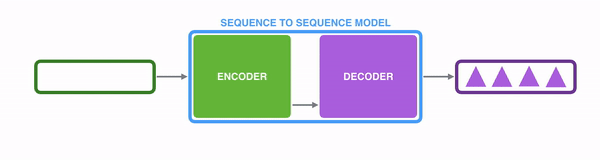
The single document summarization adopts an encoder-decoder architecture to encode the input fulltext and decode the output on the fly to abstractively generate a summary. To start off the process the user gives the machine a text to summarize. Then the machine reads and analyzes it using an attention score. Attention score is based on the material used in training the machine. It analyzes the relationship of words and phrases and the writing style. Then using this experience it writes down the first word. To continue the sentence the machine uses the probability and generates each next word until the end of the sentence. The process is repeated until the full summarization is done.
The single document summarization and multi document summarization have the same base, but the multi document summarization has an additional layer.
To create a multi document summary we scan all the documents and based on their content we rank the sentences on the importance in the article. Once the sentences are ranked, we choose the most important once across all articles and stitch them together to form a new text. Then we use a single document summarization process to create an abstractive summary.
The summary can create some biases. For example if the user chose five articles and one article is significantly different then the rest it can create a confusion to the summarization model. This happens because the contribution from the other articles will create a larger probability for the text generation for the summary and therefore create a bias toward the article that had different conclusions. As a result the content from the article that is very different from the others may not be well summarized. Hence when creating a multi document summary it is important to choose the articles based on a similar topic.
In Iris.ai Summarization tool we use the evaluation model that can classify whether the fact presented in the summary is correct or not. The model is still in the experimental stage and we are still trying to regulate the factual error that is generated by the machines. To fight with the factuality issue of abstractive summarization we are building a knowledge graph to help us generate the text that is more factually correct.
Future steps
We have already made steps towards improving our summarization model. Firstly we want to train the model with knowledge graphs to improve the factuality and the assessment so the user can understand and verify the factuality of the generated summary. Another point on our roadmap is to create topic tailored summarization. The goal is for users to be able to provide context e.g. specific entity (drug, material, etc.) and the machine will apply higher importance to the information about said entity as opposed to usually objectively assessing which information is central to the whole article. Lastly, we want to develop audience tailored summarization. Language of the generated summary would adjust depending on the type of audience and their level of knowledge in the research field. The machine could use simpler language for the students and more advanced and for experienced professors or field professionals.