INTRO TO THE EXTRACT TOOL
HOW EXTRACTING DATA WORKS
The PDF containing the relevant data points to be extracted is sent to the Iris.ai system. This PDF can be a patent, a clinical trial report, a research paper or any other relevant type of scientific or technical content. It can be one simple document at a time, or hundreds or thousands of them in a batch.
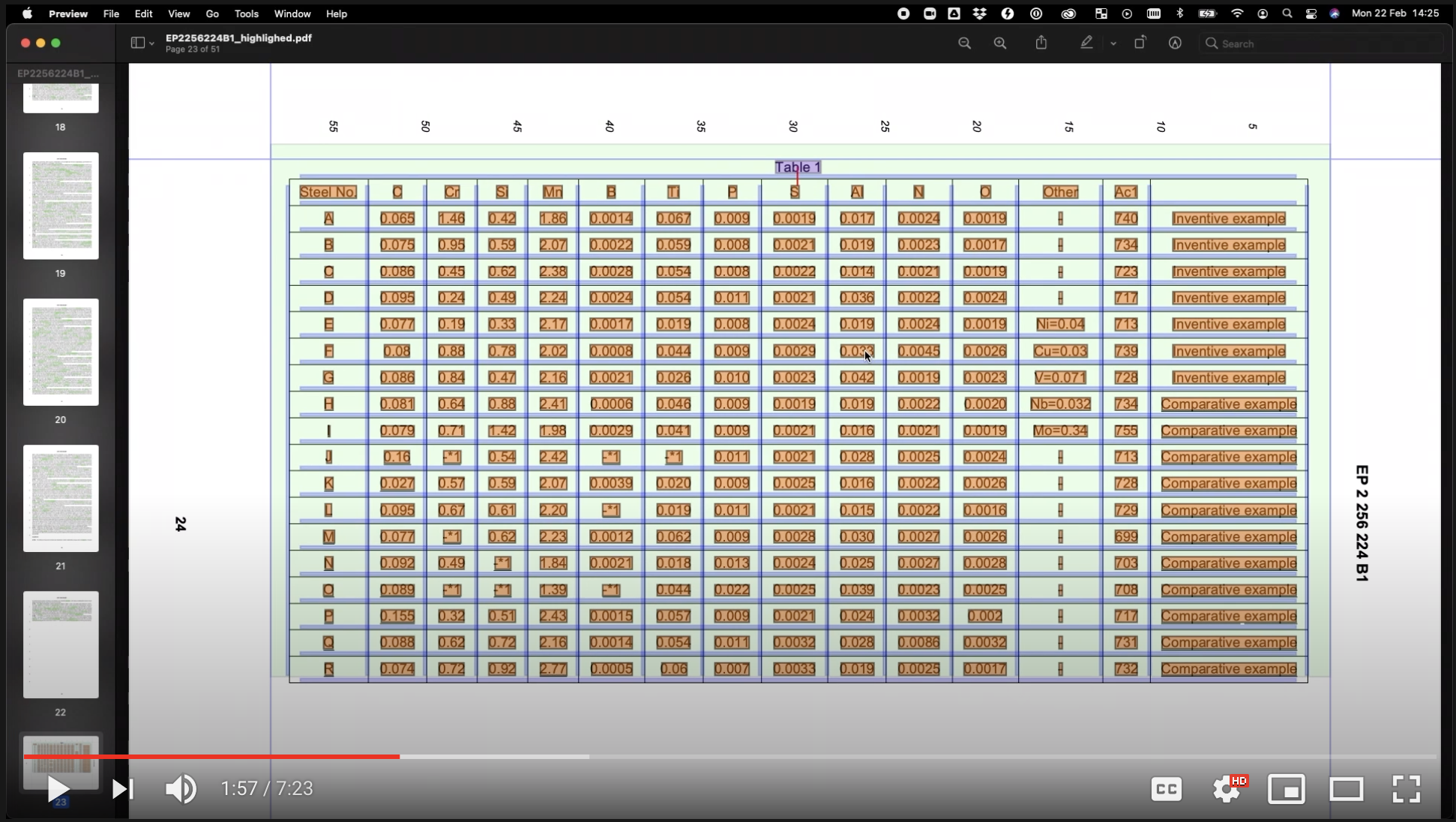
The Iris.ai engine extracts the text and identifies all the domain-specific entities, then locates the tables and extracts the data from rows and columns, and links the data between the text and table. Graphs, figures and other elements go through the same process.
Then the engine populates a pre-defined output in a machine-readable format; an excel sheet, an integrated lab tool, a database or anywhere else your researchers require.
The tool can be easily custom trained on your domain, and can thus be used for a range of topics such as chemistry, material science, pharmaceuticals, medical science and many other areas.
Customer story
![]()
Build business value through a database of material data
Need: In order to establish their services, the organization started manually extracting composition, recipe, and corresponding properties data from 50,000 research papers.
Solution: An initial database was established where the data from the 50,000 articles were extracted, systematized, and recorded by the Iris.ai Extraction tool. In the Researcher Workspace, a workflow will enable the several thousand new papers published every year to be identified and extracted automatically.

Customer story

Unique competitive advantage through experiment analysis
Need: In order to properly understand the competitor landscape, they need to extract and systematize the experiment data from each published patent.
Solution: The Extract tool allows each researcher, through a simple drag-and-drop effort, to automatically extract all experiments data from a patent and fill it into an organized layout. Experiments and corresponding outcomes are grouped, units are aligned and a confidence score gives the researcher knowledge on accuracy.
Weeks of manual labor can now be done in minutes, at human level accuracy (94% precision / 83% recall), and the team can do more extensive landscape analysis.


WHY IRIS.AI?
Iris.ai has spent the last 5 years building an award-winning AI engine for scientific text understanding. Our algorithms for text similarity, tabular data extraction, domain-specific entity representation learning and entity disambiguation and linking measure up to the best in the world. On top of that our machine builds a comprehensive knowledge graph containing all entities and their linkages to allow humans to learn from it, use it and also give feedback to the system. Applying these on scientific and technical text is a complicated challenge few others can achieve.
The Researcher Workspace
Company
Legal
The AI researcher.
AI tools and applications to allow humans to make sense of all of the world’s scientific knowledge — and apply it.
Share
© 2015-2023 Iris.ai AS. All rights reserved.