You're Running an LLM. But Do You Actually Know If It's Working?
You’ve successfully deployed the model. Your team optimized the prompt, tuned the architecture, developed the data pipeline, and pushed it to production. But how do you know if it’s actually working?
Most engineering teams ship an LLM into production and move on. They have no systematic way to measure whether the LLM output quality is genuinely good. We call this the evaluation blind spot. If you want to secure actual enterprise AI ROI, this is the practical guide you need before your next deployment.
Why Evaluation Gets Skipped (or Matters?)
Let’s be honest: LLM evaluation enterprise workflows are unglamorous. There is no obvious dashboard that flashes green when an LLM reasons correctly. Because of this gap, teams default to user feedback as a proxy for quality.
The problem is that user feedback catches failures after the fact, not before. Most teams only discover output quality issues when something goes visibly wrong, such as a hallucination surfacing in a customer-facing tool, or a wrong synthesis reaching a decision-maker. It is a common operational reality, but it leaves your systems highly vulnerable.
Many teams skip proper LLM evaluation because they start in the wrong place: with the model first, and the data, context, and domain rules later. The early experience often feels impressive because a general-purpose LLM can produce fluent answers quickly, especially for simple prompts or broad knowledge tasks. To validate quality, some teams use “LLM-as-a-judge,” where another LLM evaluates the generated response. This can be useful for lightweight checks, but it becomes fragile when the use case depends on technical, regulated, or domain-specific knowledge. This becomes even more problematic when it comes to regulated industries and data sensitive information.
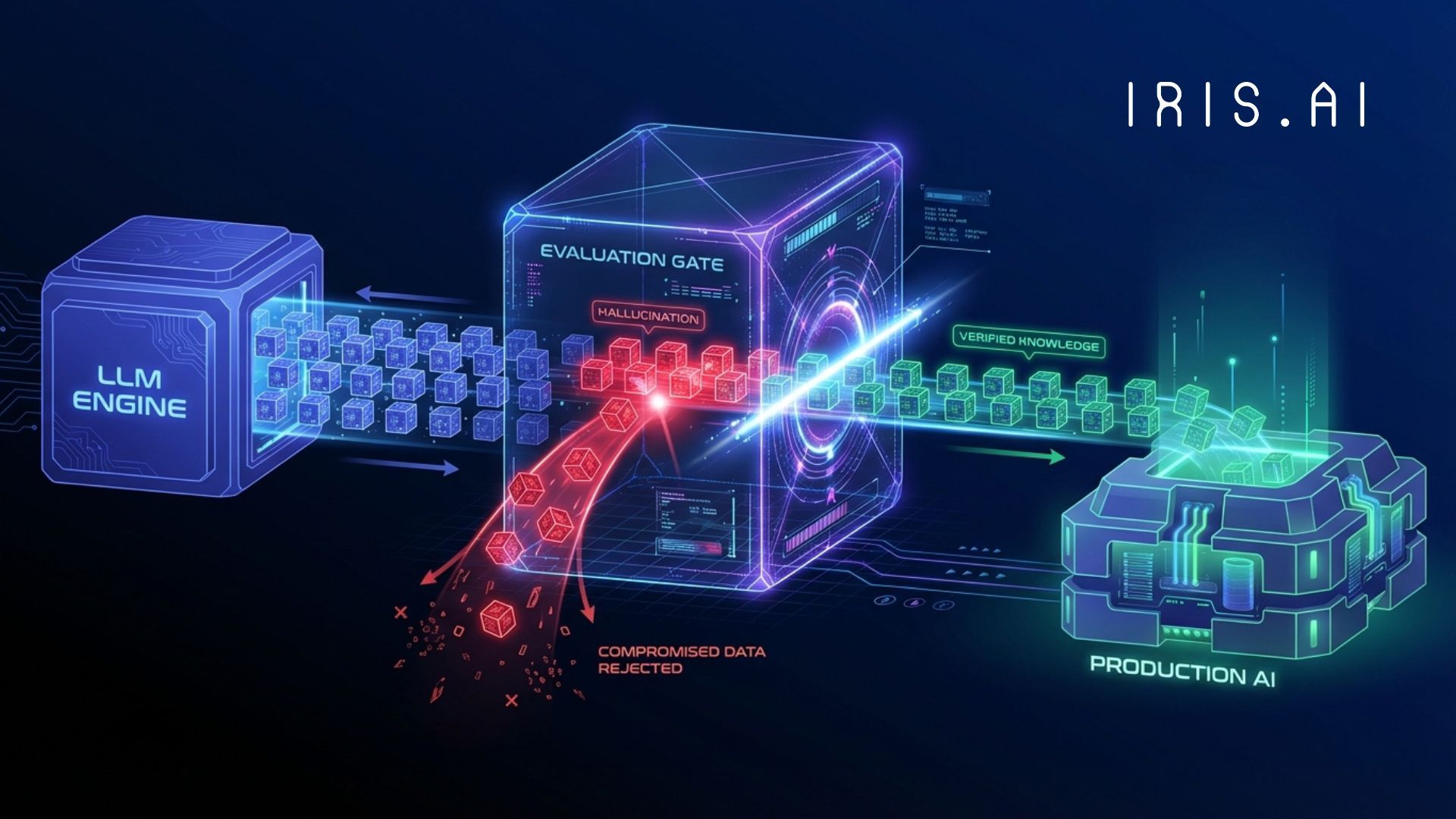
Economically, it also becomes expensive fast: using another LLM to judge thousands of queries per day adds recurring inference cost without necessarily improving trust. Enterprises need an evaluation approach that is not only accurate, but scalable: grounded in structured knowledge, expert-defined context, deterministic criteria, and measurable quality control
What to Actually Evaluate
Figuring out how to evaluate LLM performance doesn't have to be an abstract academic exercise. Based on our comprehensive LLM Evaluation White Paper, you should focus on four core dimensions:
- Factual accuracy: Does the output reflect what is actually in the source knowledge? Failure looks like a model confidently stating a product feature that your company discontinued three years ago.
- Relevance: Is the output answering the actual question asked, not just a similar one? Failure looks like an LLM summarizing a 50-page legal contract when the user only asked for the termination clause.
- Consistency: Does the same query produce stable outputs across runs? Failure looks like a financial forecasting agent giving three different revenue projections for the exact same prompt.
- Source fidelity: Can outputs be traced back to a specific, verifiable knowledge source? Failure looks like a model providing a highly technical answer without any link to the underlying source data.
What Affects YOUR Results TODAY
As we recently discussed on our podcast, three distinct levers determine your LLM output quality:
- Prompt design: How the query is structured affects what the model retrieves and generates.
- Model selection: Different models have different strengths for different task types.
- Core dataset quality: The training or retrieval data the model draws upon.
The first two levers get the vast majority of the attention, but the third is where most enterprise failures actually originate. If your underlying knowledge is trapped in unstructured data / dark data, fragmented, outdated, or completely ungoverned, no amount of prompt engineering fixes that.
When you go to change your prompt or your core dataset, that data quality is the missing piece. This is exactly where Iris.ai steps in to address the dataset quality problem as well, ensuring your fact-based models are reliable.
Iris.ai offers a managed software service that systematically improves the quality of enterprise agents by measuring the actual outputs against the knowledge, context, and business rules they are supposed to follow. Instead of relying on subjective LLM judgment alone, Iris.ai evaluates agent performance through economic and mathematical quality signals, such as factual accuracy, relevance, consistency, and source fidelity in the above.
This means enterprises can quantify whether an answer is correct, useful, repeatable, and traceable before scaling it across thousands of users or workflows, both internally and externally. This method provides enterprises with the FULL CONTROL and cost-efficient path to production AI. Improving output quality over time while reducing hallucination risk, evaluation cost, and the operational burden of manual review.
What CTO or Head of AI Should Do Next?
Evaluation is not a one-time audit; it is an ongoing infrastructure decision. To avoid the high failure rates outlined in reports like McKinsey's The State of AI, here are three concrete first steps you can take this week:
- Define your quality threshold before you optimize: Know what "good" looks like for your specific use case.
- Build a lightweight eval loop: Even a 20-query benchmark run weekly catches model drift before it compounds. Establishing strong AI governance early is critical.
- Audit your core dataset: Quality inputs determine quality outputs, full stop. Ensure you are operating on a robust AI data foundation.
See How Iris.ai Evaluates and Improves Your Knowledge Foundation - Read our White Paper